Ebben a tananyagrészben a forráskód áttekinthetőségéről és tagolásáról lesz szó.
Előző tananyagrész: első program
Következő tananyagrész: változók, konstansok, literálok
Blokkok, indentálás
Bár egy néhány sorból álló példaprogram jó eséllyel akkor is átlátható lenne, ha a main függvényt a tartalmával együtt egyetlen sorba írnánk, nem árt már most tisztában lenni azzal, hogy a viszonylag több (pl. több száz, több ezer) sorból álló forráskódokat hogyan érdemes tagolni.
Egy blokkon belül lévő sorokat általában 2 vagy 4 szóközzel, esetleg egy tabulátorral beljebb kezdjük a könnyebb átláthatóság érdekében. Ezt indentálásnak nevezzük. Példa:
Így írjuk:
int main() {
/*utasitas1;
utasitas2;
utasitas3;*/
}Ehelyett:
int main() {
/*utasitas1;
utasitas2;
utasitas3;*/
}Vagy ehelyett:
int main() { /*utasitas1; utasitas2; utasitas3;*/ }A szóközöket, tabulátorokat ne keverjük, vagyis ha például 4 szóközt használunk indentáláshoz, akkor a program összes forrásfájljában tegyünk így.
Több utasítás egy sorba írása kerülendő.
Mit tekint a sor végének a fordító?
Bár elsőre kicsit furcsának tűnhet a kérdés, valójában csak arra szeretném felhívni a figyelmet, hogy a forráskód hosszú sorai például egy honlapon vagy egy pdf dokumentumban több sorba lehetnek tördelve, de attól az a fordító szempontjából még egy sornak számít.
Ezen a képen jól látszik, hogy ennek a forráskódnak a negyedik sora egy hosszú szöveget tartalmaz, ez igazából csak egyetlen sor, de a kép jobb oldalán a gedit text editor több sorba tördeli:
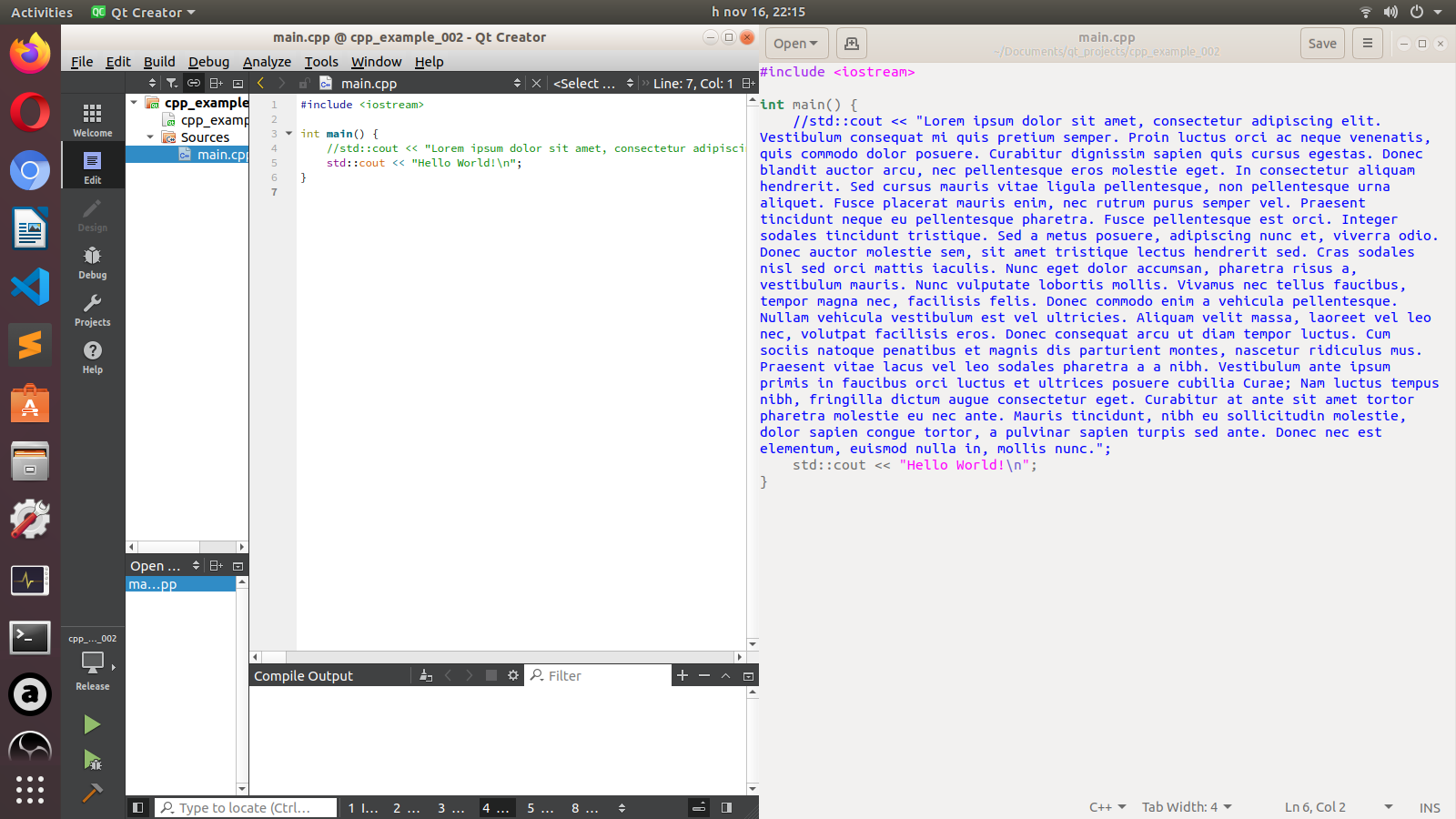
Ha például mobiltelefonon nézegetünk forráskódokat tartalmazó szöveget, könnyen megeshet, hogy tördelve lesznek a sorok, ami adott esetben az olvashatóságot is nehezítheti.
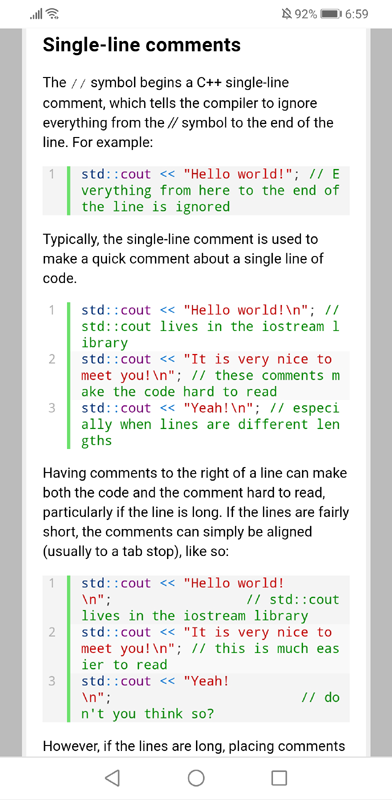
a képen a learncpp.com - comments cikke látható
A fordító csak azt tekinti sor végének, ahol sorvége jel szerepel. Például ha megnyomjuk az enter billentyűt a billentyűzeten a forráskód írásakor, akkor egy sorvége jel keletkezik, vagy ha mondjuk ctrl+c és ctrl+v segítségével bemásolunk egy olyan szöveget, amiben szerepel sorvége jel.
Ha csak azért látunk egy szöveget két vagy több sorban, mert egy honlapon vagy egy szövegszerkesztőben, dokumentumszerkesztőben nem fér ki egy sorba, de nincs benne sorvége jel, akkor azt a fordító egy sornak fogja tekinteni.
Vannak olyan szövegszerkesztők, ahol ki lehet kapcsolni a hosszú sorok tördelését. Angolul ezt word wrap vagy text wrap beállításként keressük.
Ha be van kapcsolva a sorok tördelése, akkor pedig esetleg segíthet ha bekapcsoljuk a sorvége jelek megjelenítését.
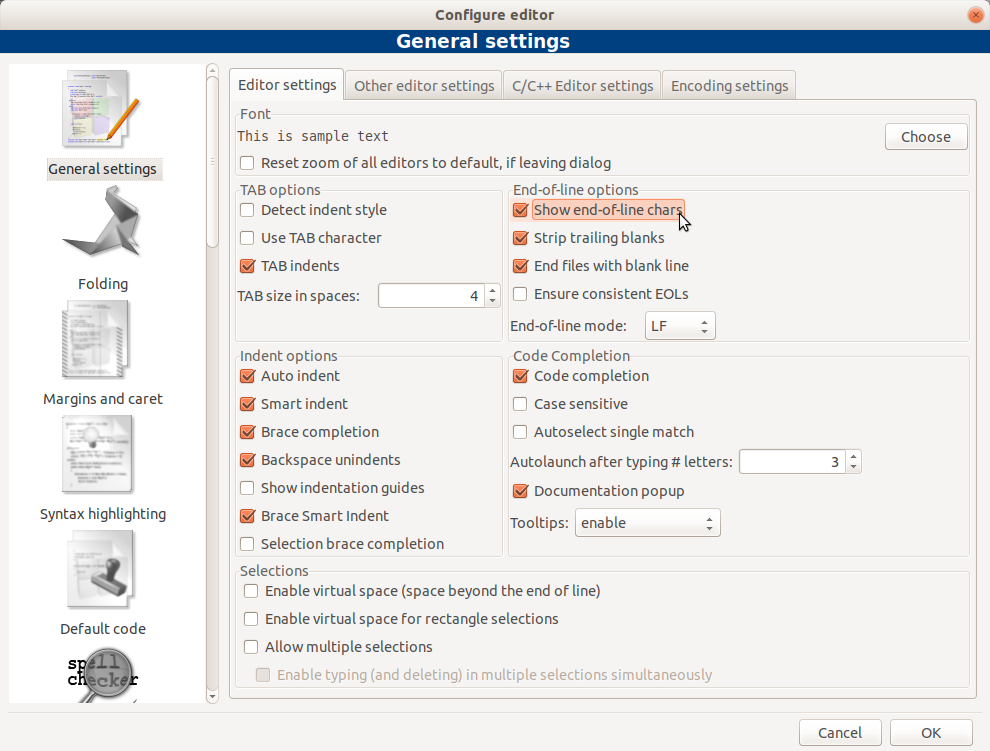
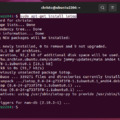
A CodeBlocks például LF rövidítéssel (line feed, soremelés) jelzi a sorvége jeleket. A képen jól látható, hogy nem minden sortörésnél van sorvége jel.

Két sor egyesítése
Ha egy sor végén \ jel szerepel (fontos, hogy ez legyen az utolsó karakter), akkor a fordító szempontjából olyan, mintha a két sor tartalma egy sorban szerepelne. Másképp fogalmazva ha a \ jel egy adott sor utolsó karaktere, akkor hatástalanítja az utána következő sorvége jelet.
Az idézőjelek közé írt szövegek, egysoros kommentek, preprocesszor direktívák csak ily módon szerepelhetnek két sorban:
std::cout << "ebben a szovegben \
nincs ujsor karakter";
//egysoros komment \
ket sorbanHa ezt beillesztjük egy parancssoros C++ program forráskódjába, majd fordítjuk és futtatjuk a programot, akkor a kimeneten láthatjuk, hogy a parancssorba kiírt szövegben nem lesz sortörés.
 Ugyanez az újsor karakterek megjelenítésével:
Ugyanez az újsor karakterek megjelenítésével:
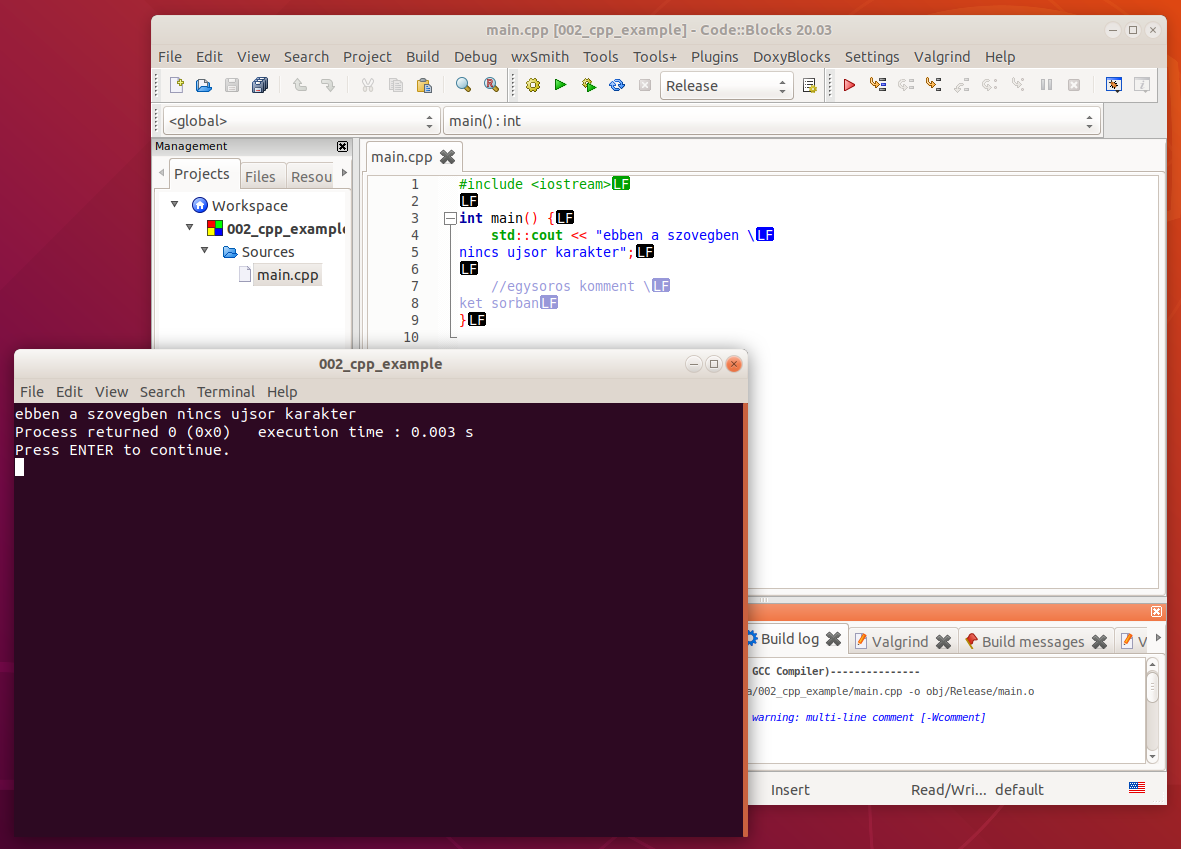
Mindkét példa esetén, ha nem írjuk ki a \ jelet a sorvége jelek elé, fordítási hibát kapunk:
std::cout << "forditasi
hiba";//forditasi
hibaKét szöveg összefűzése a forráskódban
Ha a forráskódban két idézőjelek közé tett szöveget egymás után írunk, az ugyanolyan, mintha a bennük szereplő szövegeket egyetlen nyitó és záró idézőjel pár közé írtuk volna. Esetleg ezt a módszert is alkalmazhatjuk a sorok tördeléséhez.
std::cout << "ebben a szovegben "
"nincs ujsor karakter";Ha + operátort teszünk közéjük (mint ahogy azt például Javascript, Java vagy C# nyelvekben megszokhattuk), akkor fordítási hibát kapunk.
Bár az std::string és az std::string literál későbbi tananyagrész témája, a teljesség kedvéért ez a két megoldás is szerepeljen itt.
Ez a megoldás más nyelvekhez hasonlóan csak + operátorral működik. Ha csak egymás mögé írjuk őket, a + operátort kihagyva, akkor fordítási hibát kapunk.
#include <iostream>
#include <string>
int main() {
std::cout << std::string("ebben a szovegben ") +
std::string("nincs ujsor karakter");
}Ez a megoldás + jellel és anélkül is működik:
#include <iostream>
#include <string>
int main() {
using namespace std::string_literals;
std::cout << "ebben a szovegben "s
"nincs ujsor karakter"s;
std::cout << '\n';
std::cout << "ebben a szovegben "s +
"nincs ujsor karakter"s;
}Szövegek összefűzését konkatenációnak nevezzük.
Raw string literálok tördelése
Az úgynevezett raw string literálok arra lettek kitalálva, hogy a tartalmuk pontosan az lesz, mint ahogy az a forráskódban kinéz. Pl. ha a forráskódban látunk egy raw string literálban sortörést, akkor a parancssorba kiírt eredményben is fogunk:
std::cout << R"(elso sor
masodik sor)";White space
Összefoglaló néven white spaceknek nevezzük a szóközt, tabulátort és sortörést. Az elnevezés onnan ered, hogy a forráskód szövegében alapvetően nem látszódnak, kivéve ha a text editorban vagy fejlesztői környezetben bekapcsoljuk a megjelenítésüket (a legtöbb text editorban és fejlesztői környezetben ez alapbeállítás szerint ki van kapcsolva).
C++ kód tördelése, tagolása (leszámítva a kommenteket, karakter-, vagy string literálokat)
A C++ forráskódban tokeneknek nevezzük azokat a dolgokat, amiket mindenképp egybe kell írni, az őket meghatározó karakterek közé nem írhatunk szóközt, tabulátort vagy sortörést (white spaceket), különben jó eséllyel fordítási hibát kapunk.
Többféle token létezik, melyekhez külön tananyagrészek kapcsolódnak: kulcsszavak, nevek/azonosítók, operátorok, szeparátorok, literálok.
Az int vagy a return például kulcsszavak, a main, az std, a cout, az endl nevek/azonosítók, a << a :: és a () operátorok, a 3.14 egy literál, a -128 egy operátor és egy literál, a main függvény különböző részeit elválasztó karakterek pedig szeparátorok, például ; { } de ez utóbbiak nem állnak több karakterből, így nem tudjuk az őket alkotó karaktereket külön írni.
Egyelőre itt most nem az a lényeg, hogy megtanuljuk, mik a kulcsszavak meg mik az azonosítók, hanem az, hogy tudjunk róla, ha például a << vagy :: karakterek közé mondjuk szóközt teszünk, fordítási hibát kapunk.
Az egyes tokenek közé tetszőleges white space írható.
Például ezt a forráskódot a fordító ugyanúgy tudja értelmezni, de nyilván az emberek számára nehezen olvasható:
#\
i\
n\
c\
l\
u\
d\
e\
<\
i\
o\
s\
t\
r\
e\
a\
m\
>
int
main
(
)
{
std
::
cout
<<
-
128
<<
'\n'
;
}Gépelési hibák, elírások
Angolul typoo. Ha a forráskódban elírunk valamit, az jó eséllyel fordítási hibát okoz. Pl. ha lehagyunk egy pontosvesszőt az egyik utasítás végéről, akkor a fordító nem tudja futtathatóvá alakítani azt a forrásfájlt, amiben a hiba szerepel. A C++ kód kis- és nagybetű érzékeny (angolul case sensitive), ha main helyett Main-t írunk az szintén fordítási hibát okoz.
Vannak olyan programozási nyelvek, ahol nem kell az utasítások végére pontosvesszőt tenni (pl. Javascript, Python), C++-ban viszont minden utasítás végére kell pontosvessző. Ez persze nem azt jelenti, hogy minden sor végére pontosvessző kell.
A preprocesszor utasítások nem a C++ nyelv része, azok végére nem kell pontosvessző. Sokszor a záró kapcsos zárójelek után sem kell pontosvessző.
Egyéb tudnivalók a parancssorba való kiíratásról
Arról már esett szó, hogy a különböző típusú dolgokat az std::cout után egy-egy << operátort követően tudjuk írni, de még kevés példa volt arra vonatkozóan, hogy milyen típusú dolgokat lehet kiíratni és milyen formában kell írni őket.
String- és karakter literálok
Ha több mint egy karakterből álló szöveget szeretnénk kiíratni, akkor a szöveget idézőjelek közt adhatjuk meg, mint a fentebbi példában is:
std::cout << "ket szo\n";(Ékezetes szövegekkel egyelőre nem foglalkozunk, arról majd külön tananyagrész fog szólni).
Egyetlen karaktert tehetünk aposztrófok közé is, akkor is, ha speciális karakterről van szó (pl. az újsor karakterről: \n):
std::cout << 'a' << ' ' << '2' << '\n';Speciális karakterek, escape karakter
Gyakran használt speciális karakter például a \t (tabulátor) is, illetve fontos tudni, hogy ha karakter vagy string literálokban szerepel \ vagy " karakter, karakter literálban ' karakter,akkor azok elé is \ karaktert kell tenni, különben jó eséllyel fordítási hibát kapunk.
std::cout << '\'' << "\t \\ \" \n";Raw string literálok
A raw string literálok olyan string literálok, amiknek az értéke pontosan úgy van értelmezve, mint ahogy azt a forráskódban látjuk (erre használják angolul a wysiwyg, azaz what you see is what you get kifejezést).
Ez annyit jelent, hogy egy raw string literálban például a \n vagy \t karakterek nincsenek speciális karakterként értelmezve, hanem hagyományos karakterekként a szöveg részei, illetve ha a forráskódban a raw string literálon belül szerepel sortörés, akkor a raw string literál értékében is lesz sortörés.
std::cout << R"(\n \t \\ ' ")";A raw string literálokat például akkor használjuk, ha sok speciális karaktert tartalmazó szöveget szeretnénk a programunkban szövegként felhasználni, pl. esetleg valamilyen forráskód szövegét.
Fontos, hogy ha a raw string literál idézőjelei között szerepelnek a )" lezárókarakterek, akkor a szöveg azt követő része hagyományos string literálként lesz értelmezve, ami esetleg fordítási hibát okozhat.
Meg tudjuk adni, hogy mik legyenek egy raw string literál nyitó- és záró karakterei, és ha olyat adunk meg, ami a szövegen belül valószínűleg nem szerepel, akkor jó eséllyel nem fog hibát okozni:
std::cout << R"%!+valami(Hello, world!\n)%!+valami";Szóköz, tabulátor
Ha több kiírni kívánt dolgot jól láthatóan el akarunk egymástól választani a kimeneten, akkor tegyünk közéjük vagy az egyes szavak végére szóközt vagy tabulátort, esetleg újsor karaktert.
std::cout << "egyik szoveg, " << "masik szoveg,\t" << "harmadik szoveg" << ' ' << "negyedik szoveg\n";Egyéb kapcsolódó tananyag
- learncpp.com - whitespace and basic formatting
- Jason Turner: trigraphs, digraphs, alternative tokens
Előző tananyagrész: első program
Következő tananyagrész: változók, konstansok, literálok