
Ebben a tananyagrészben arról lesz szó, hogy hogyan tudunk a legegyszerűbben adatokat tárolni egy programon belül, hogyan lehet a parancssoros programokban a felhasználótól adatokat bekérni, és hogy hogyan lehet ezeket az adatokat a parancssorba kiíratni. Ehhez a tananyagrészhez szorosan kapcsolódik a következő néhány tananyagrész.
Előző tananyagrész: várakozás enter billentyű megnyomásáig
Következő tananyagrész: gyakori műveletek
Tartalom
- deklaráció, definíció
- naming rules
- inicializálás
- változók értékének kiíratása
- értékadás (operator=)
- bekérés (std::cin, getline, input buffer, standard input)
- konstans (const)
- preprocesszor makrók
- literálok
- kifejezések (értéke, típusa)
- temporálisok
- példaprogram
Egyéb
Alapvető tudnivalók
Memória, háttértárolók
Minden program adatokkal dolgozik, adatokat dolgoz fel. A feldolgozás alatt lévő adatok a számítógép memóriájában (az úgynevezett RAM-ban) vannak tárolva. Az operációs rendszer minden futó programnak ad valamekkora részt a számítógép memóriájából, ahol az egyes programokhoz tartozó, feldolgozás alatt lévő adatok tárolhatóak.
Ha kikapcsoljuk a számítógépet, vagy valamilyen hiba miatt leáll a számítógép, törlődik annak a memóriának a tartalma, ahol az egyes programokhoz tartozó feldolgozás alatt lévő adatok tárolódnak.
A megőrízni kívánt adatokat háttértárolókon, fájlokban tároljuk. (A felhőben tárolt adatok is háttértárolókon vannak fájlokként tárolva, csak azokat a háttértárolókat távoli számítógépek kezelik).
Természetesen a számítógép memóriája, ahol a feldolgozás alatt lévő adatokat tároljuk, sokkal gyorsabb, de sokkal kisebb is, mint a megőrízni kívánt adatok számára fenntartott háttértárolók. Ez nyilván érthető, mivel érdemes annak gyorsabbnak lennie, ami épp feldolgozás alatt áll, és mivel általában több a megőrízni kívánt adat, ezért a háttértárolók nagyobbak.
A számítógépben található olyan memória is, ami az operációs rendszereken (pl. Windows, Linux) futó programok feldolgozás alatt lévő adatait nem tárolja, például az úgynevezett ROM, amiben a számítógép legalapvetőbb működéséhez szükséges dolgok vannak, de az nem ennek a tananyagnak a témája.
Milyen adatokkal dolgozik egy program?
Az eddigi példaprogramjainkban a példaprogramok forráskódjába beleírtuk azokat az adatokat, amikkel a program dolgozik. Ezeket nevezzük literáloknak.
Nyilvánvalóan ez a módszer, hogy beleírjuk a forráskódba azokat az adatokat, amikkel a program dolgozik, önmagában nem lenne túl célszerű, például azért, mert azokat az adatokat valószínűleg csak a programozók tudnák módosítani.
(Ennek ellenére a tananyagban lesznek olyan példák, amiknek a forráskódjába beleírjuk azokat az adatokat, amikkel a program dolgozik, nem pedig a felhasználótól kérjük be, azért, hogy ezek az egyszerű példaprogramok gyorsabban kipróbálhatók legyenek).
A legtöbb program az adatokat, amikkel dolgozik a külvilágból (a program futtatható fájljához képest) szerzi. Néhány példa:
- egy parancssoros programban a program futásának azokon a pontjain, amikor a program adatokat kér be, a felhasználó be tudja gépelni a program által feldolgozandó adatokat
- egy tetszőleges felületű (pl. parancssoros, ablakos, 2d/3d grafikus) program tud fájlból beolvasni adatokat
- egy tetszőleges felületű program a számítógép órájának adatait lekérheti
- egy tetszőleges felületű program adatbázisból (pl. mysql) kérheti le a feldolgozandó adatokat
- egy tetszőleges felületű program hálózati adatokat dolgozhat fel (pl. a boost asio library segítségével)
- egy ablakos program pl. egy ablakban elhelyezett input mezőbe (pl. textbox vagy lineedit) a felhasználó által beírt adatot tudja feldolgozni, tipikusan például egy gomb megnyomását követően
- egy grafikus (ablakos 2d/3d grafikus) program az egérkurzor koordinátáit és pl. a kattintás időpontját tudja felhasználni
Ebben a tananyagban természetesen csak parancssorban megvalósítható példákkal foglalkozunk.
Adatok a programon belül
A programok nagy része nem egy lépésben állít elő egy bemenetből egy kimenetet, hanem sok részeredményen keresztül. Továbbá sokszor előfordul, hogy egy program egy adatot többször felhasznál, egy adatra többször is hivatkozik. Ha csak literálokat használnánk, ezt sem tudnánk megtenni.
A magasszintű programozási nyelvekben a programok forráskódjában valamilyen nevet/azonosítót (angolul identifier) adunk (nyilvánvalóan könnyebb nevekkel dolgozni mint memóriacímekkel) azoknak az adatoknak, amikre például többször is szeretnénk hivatkozni (pl. több műveletet akarunk vele végezni vagy többször ki szeretnénk íratni), vagy azoknak, amiket például parancssorból, fájlból, egyéb helyekről olvasunk be, akkor is, ha csak egyszer hivatkozunk rájuk. Sokszor előfordul, hogy azoknak az adatoknak is adunk nevet, amikre egyetlen egyszer hivatkozunk csak, bár vannak ellenérvek, ellenpéldák, egyes esetekben átláthatóbbá teheti a kódot.
Fontos megjegyezni, hogy ezek a nevek a forráskódban léteznek, a futtatható programba csak akkor kerülnek bele, ha fordításkor be van kapcsolva a debug információkkal történő fordítás.
Változók
Egy változó (angolul variable) a program futásának egy adott pillanatában egyetlen adat tárolására alkalmas. Minden változónak kell egy nevet adni a változó létrehozásakor (angolul ezt a nevet szokták identifiernek, vagyis azonosítónak hívni), és egy változóban tárolt adatra a változó nevével tudunk hivatkozni.
Egy változóban tárolt adat tipikusan például egy karakter, egy egész szám, egy valós szám, egy logikai érték (igaz/hamis) vagy valamilyen több karakterből álló szöveg (úgynevezett karakterlánc, vagy angolul string) lehet.
A változó elnevezés onnan ered, hogy a benne tárolt adat utasításról utasításra megváltoztatható, másképp fogalmazva minden egyes utasításban (vagyis tetszőleges alkalommal) adhatunk egy változónak új értéket, akár az előző érték felhasználásával (pl. egy szám esetén hozzáadunk 1-et a változó addigi értékéhez, vagy mondjuk egy karaktert kisbetűsítünk vagy nagybetűsítünk).
Változók deklarálása, definiálása
A C++ nyelvben egy változó első használata (pl. az értékének a kiíratása vagy módosítása) előtt jelezni kell, hogy a változót létre szeretnénk hozni (ez nem minden programozási nyelvben van így, pl PHP nyelvben ha elkezdünk használni egy változót akkor ha az a változó még nem lett létrehozva, automatikusan létrehozásra kerül). Ezt úgy tehetjük meg, hogy leírjuk a típusát és a nevét. Például:
char variable1;Ha például ez az utasítás szerepel egy blokkban (pl. a main függvény kapcsos zárójelei között) valahol, akkor abban a blokkban ezen utasítást követően használhatjuk ezt a karakter típusú, variable1 nevű változót egészen a blokk végéig.
A C++ nyelvben egy változó típusa nem változtatható meg. Ha például intként (egész számként) hoztunk létre egy variable2 nevű változót, akkor az a változó, amíg létezik, int típusú marad. A benne tárolt értéket persze átmásolhatjuk pl. egy double (valós szám) típusú változóba. (Esetleg egy másik blokkban (kapcsos zárójelek közti részben) létrehozhatunk egy ugyanilyen nevű változót más típusúként, az viszont megtévesztő, és éppen ezért kerülendő is).
(Ez sem minden programozási nyelvben van így, például a Javascript és a PHP nyelvekben egy változóban bármilyen típusú érték tárolható, vagyis előfordulhat, hogy pl. egyszer egy egész szám értéket tárolunk el egy változóban, majd később egy stringet. Sőt, ezekben a nyelvekben valójában nem a változónak van típusa, hanem a változó aktuális értékének.)
Az első példaprogramjainkban legfőképpen az úgynevezett alaptípusú változókkal végzünk néhány egyszerű műveletet, a C++ nyelvben szereplő alaptípusok összesítő listáját például itt találjuk, de az első példaprogramokban ezek közül is csak a legegyszerűbbekről, legáltalánosabbakról lesz szó. Ezek:
- char - karakter
- int - egész szám (angolul integer)
- double - valós szám
- bool - logikai típus (későbbi tananyagrész témája)
Az intnek és a doublenek léteznek kisebb és nagyobb változatai (short int, long int, long long int, illetve float és long double), az intnek pedig létezik negatív számokat nem tartalmazó (unsigned int) változata is. Ezekről az alaptípusok jellemzői tananyagrészben lesz részletesebben lesz szó.
Néhány alaptípusú változó létrehozása (ezeket az utasításokat például a main függvény blokkjába írhatjuk):
char variable1;
int variable2;
double variable3;
bool variable4;Mivel azért a több karakterből álló szövegek (úgynevezett stringek vagy karakterláncok) kezelése is eléggé alapvető igény, így erre is nézünk példát a legelső példaprogramjainkban, de már most szeretném kihangsúlyozni, hogy a C++ nyelvben történeti okokból több string típus létezik, és az ezek közti átjárhatóság nem egyszerű téma, úgyhogy erről majd egy külön tananyagrész fog szólni.
Az std::string típus szövegek tárolására, kezelésére alkalmas, de mivel nem alaptípusú változó, így a fenti listából kimaradt:
- std::string - szöveg, karakterlánc (részben későbbi tananyagrész témája)
Az alaptípusú változókhoz hasonlóan hozhatunk létre std::stringet is:
std::string variable5;Viszont ne felejtsük el includeolni a string header fájlt:
#include <string>Noha előfordulhat, hogy bizonyos fordítókat használva ennek hiánya esetén tudunk std::stringet használni, viszont elképzelhető, hogy ebben az esetben bizonyos műveletek, amik az std::string típushoz kötődnek, nem fognak helyesen működni, ezért ajánlott ennek a preprocesszor utasításnak minden forrásfájlban szerepelnie, ahol std::string típusú változókat szeretnénk használni.
Egy utasításban több azonos típusú változót is létrehozhatunk:
int a, b, c;Ennek ellenére vannak, akik szerint minden változót külön utasításban, külön sorban érdemes létrehozni a jobb átláthatóság érdekében.
Mi a különbség a deklaráció és a definíció között?
A definíció jelenti a változó létrehozását, az adott típus számára szükséges memóriaterület lefoglalását, a deklaráció pedig önmagában csak annyit jelent, hogy tájékoztatjuk a fordítót, hogy egy bizonyos típusú és nevű változó valahol már létezik (pl. egy másik fájlban), de itt (ahol a deklarációra vonatkozó utasítás szerepel) is használni szeretnénk.
Gyakran előfordul, hogy valaki a deklarálás szót használja a definiálás szó jelentésével, vagyis a deklarálás alatt érti egy változó létrehozását, a számára szükséges memóriaterület lefoglalását. Bár a C++ nyelvben a legtöbb deklaráció definíció is egyben (pl. a függvények blokkjában deklarált/definiált változók, amiket lokális változóknak, vagy esetleg automatikus változóknak is szoktak nevezni), mégsem teljesen precíz deklarációnak (és nem definíciónak) nevezni például a main függvény (vagy bármilyen másik függvény) blokkjában elhelyezett char example_variable; vagy int example_variable2; utasításokat.
A globális változók és az osztályok statikus adattagjai esetén a deklaráció önmagában nem elégséges, ezeket definiálni is kell, különben fordítási hibát kapunk, de ezek későbbi tananyagrész témái. (Osztályok statikus adattagjai esetén a C++17-es vagy újabb szabványokban már használhatunk úgynevezett inline változókat, de ez már nagyon elrugaszkodik a jelenlegi tananyagrész szintjétől).
Csak a példa kedvéért a globális változók esetén a deklaráció és a definíció között így néz ki a különbség (ezen példa esetén feltételezzük, hogy a variable2 egy másik fájlban van definiálva):
//definicio:
int variable1;
//deklaracio:
extern int variable2;
int main () { /*utasitasok*/ }Ha a linker nem talál a variable2-höz definíciót (akár egy másik fájlban), akkor fordítási hibát kapunk.
Egyébként globális változókat használni a legtöbb esetben ellenjavallt [2], így emiatt sem túl szerencsés, hogy pont ez az egyik példa ami esetén van különbség egy változó deklarációja és definíciója között.
Deklaráció vs definíció témával kapcsolatos egyéb olvasnivalók:
(Előfordulhat, hogy a függvények deklarációja és definíciója közti különbségről is szó esik bennük).
- cplusplus.com - Declare vs Define in C and C++
- stackoverflow.com - difference between a definition and a declaration
- stackoverflow.com - Declaration vs definition in C
- stackoverflow.com - Static variable declaration and definition
Miért van az, hogy egyes tananyagokban teljesen mást írnak a deklaráció és definíció közti különségről? Nos, ez jó eséllyel azért van, mert ez különböző programozási nyelvek esetén eltérő lehet.
A fenti leírás a C és C++ nyelvekre jellemző, de például Javascript nyelvben ha nem adunk kezdőértéket egy változónak, akkor a változót csak deklaráltuk, és nem definiáltuk (hiszen az értéke undefined). A Javascript nyelvben ez azért van így, mert ott nem a változóknak van típusa, hanem a változók értékének.
Változók elnevezésének szabályai
Minden változónak kell valamilyen nevet/azonosítót (angolul identifier) adnunk a létrehozásakor. Ez a név nem lehet teljesen tetszőleges, be kell tartanunk bizonyos szabályokat.
A változók neve...
- nem kezdődhet számmal
- nem tartalmazhat szóközt
- egyedi kell, hogy legyen (egy blokkon (kapcsos zárójeles részen) belül nem lehet két azonos nevű változót létrehozni)
- nem lehet azonos a C++ nyelv kulcsszavaival (más néven foglalt szavaival)
Ha ezeket nem tartjuk be, fordítási hibát kapunk.
Ezek a szabályok egyébként nem csak a változók neveire érvényesek, hanem az egyéb dolgok (pl. tömbök, függvények, osztályok, objektumok, satöbbi) neveire is.
Az utolsó szabályt leszámítva ezek a szabályok érvényesek a preprocesszor makrókra is.
Továbbá érdemes figyelni arra, hogy...
- a változók neveiben (mint ahogy egyébként a teljes forráskódban is) számít a kis- és nagybűk közti különbség (angolul case sensitivity)
- ne kezdődjenek alsóvonallal az általunk létrehozott változók (és egyéb dolgok) nevei, mert akkor ütközhetnek az előre definiált változók (és egyéb dolgok) neveivel
- ne tartalmazzon a változók (és egyéb dolgok) neve két egymást követő alsóvonalat
Noha a C++ szabvány nem tiltja a speciális karakterek, unicode karakterek, ékezetes karakterek használatát a változónevekben, de előfordulhat, hogy valamelyik tananyagban azt olvashatjuk, hogy a változók neve csak az angol abc betűiből, számokból és alsóvonalból állhat, amire mondjuk lehet ellenpéldákat mutatni, de mindenesetre érdemes betartani.
Témához kapcsolódó részletesebb olvasnivalók:
Szintén ehhez a témához kapcsolódik, hogy milyen neveket érdemes adni a változóknak, erről itt találunk néhány információt:
Kezdőérték, inicializálás
Kezdőértékadásnak vagy inicializálásnak nevezzük, ha egy változó definiálásával (létrehozásával) egy utasításban adunk értéket a változónak.
Például ennek az utasításnak az a jelentése, hogy létrehozunk egy int típusú, variable nevű változót, aminek az értéke 1 lesz (amíg meg nem változtatjuk):
int variable = 1;Egy változó felveheti egy másik változó értékét kezdőértékként:
int variable1 = 10;
int variable2 = variable1;Ha esetleg egy utasításban több változót hozunk létre, akkor mindegyiknek adhatunk külön-külön kezdőértéket.
double a = 3.2, b = -9.7, c = 10.004;Számos programozási nyelvben a kezdőértékadást nem egy szokásos értékadásnak, hanem egy speciális műveletnek tekintjük. Bár az alaptípusú változók esetén ezen példa két sora egyenértékű, amikor majd osztályokkal, objektumokkal dolgozunk, akkor a kezdőértékadás egy konstruktorhívást fog jelenteni, az értékadás pedig jelenthet copy konstruktor hívást, vagy az operator= meghívását.
int a = 0;
int b; b = 0;A kezdőértékadás módjai
Egyenlőségjel operátorral (angolul assignment operator):
char variable1 = 'a';
int variable2 = 1;
double variable3 = 2.0;
Kerek zárójellel:
int variable1(1);
int variable2 = int(1);A kerek zárójeles inicializáláshoz kapcsolódik a C++ nyelv egyik leghírhedtebb hibája, az úgynevezett most vexing parse, ezért ennek a használatát sokan nem tanácsolják.
Kapcsos zárójellel:
int variable1 = {1};
int variable2{1};Fontos tudni, hogy a kapcsos zárójeles inicializálással szűkebb értéktartományon értelmezett változónak egy bővebb értéktartományon értelmezett típusú kifejezést nem lehet kezdőértékül adni (ezt nevezik angolul narrowing conversionnek). Például ha kapcsos zárójeles inicializálással egy double típusú értéket adunk kezdőértékül egy int típusú változónak, akkor fordítási hibát kapunk.
//error
int variable{3.7};//error
double variable1{6.2};
int variable2{variable1};Egyenlőségjellel ugyanez viszont működik:
double variable1 = 34.78;
int variable2 = variable1;Ekkor a variable2 nevű változó értéke 34 lesz.
Nicolai Josuttis, The Nightmare of Initialization in C++ (33:36)
A kerek- és kapcsos zárójeleket csak kezdőértékadáshoz lehet használni, további értékadásokhoz nem, azokhoz csak az egyenlőségjel használható.
//error
int variable;
variable{128};Kivétel:
int variable;
variable = {128};Egyéb: fordítási hibát kapunk ha std::string típusú változónak char típusú kezdőértéket adunk egyenlőségjel operátorral vagy kerek zárójellel, a kapcsos zárójeles módszer viszont működik.
//error
std::string variable1 = 'a';
std::string variable2('a');//no error
std::string variable{'a'};Ezeknek a különböző módszereknek az angol elnevezéseit itt találhatjuk:
Melyik módszert érdemes használni kezdőértékadáshoz?
A legtöbb esetben a kapcsos zárójeles inicializálás használatát szokták javasolni, vannak azonban kivételek.
Például ha egy bővebb tartományon értelmezett típusú értéket szeretnénk adni egy szűkebb tartományon értelmezett változónak (pl. egy double típusú értéket egy int típusú változónak).
Nem alaptípusú változók esetén előfordulhat, hogy a kapcsos zárójeles kezdőértékadás nem az elvárt működést eredményezi. Például:
#include <iostream>
#include <string>
int main() {
std::string variable1(40,'-');
std::string variable2{40,'-'};
std::cout << variable1 << '\n';
std::cout << variable2 << '\n';
}Ebben a példában a kerek zárójeles inicializálás az első paraméterben megadott számnak megfelelő darab második paraméterben megadott karaktert ad értékül a stringnek, a kapcsos zárójeles inicializálás viszont az első paraméterben megadott számot átkonvertálja karakterré, majd ahhoz hozzáfűzi a második paraméterben megadott karaktert.
- ithub.hu - a C++ és a zárójelek
- Nicolai Josuttis - couple of ways to initialize an int (videó)
- C++ Weekly - std::string's Confusing Constructors (videó)
Milyen kezdőértéket érdemes adni a változóknak?
Nulla vagy nullával egyenértékű kezdőértékadás (angolul zero initialization)
A változóinknak sokszor 0 vagy nullával egyenértékű kezdőértéket adunk. Például:
char variable1 = '\0';
int variable2 = 0;
double variable3 = 0.0;
bool variable4 = false;Ezekkel az utasításokkal teljesen egyenértékűek az alábbi utasítások:
char variable1 = char();
int variable2 = int();
double variable3 = double();
bool variable4 = bool();Szintén egyenértékű, ha kapcsos zárójeles kezdőértékadást használunk, és a kapcsos zárójelben nem adunk meg paramétert, vagyis üresen hagyjuk:
char variable1{};
int variable2{};
double variable3{};
bool variable4{};Nullával való osztás elkerülése
Előfordulhat, hogy egész szám, és valós szám típusú változóknak -1-et adnak kezdőértékül, a 0-val való osztás elkerülése céljából.
int variable8 = -1;
double variable9 = -1.0;Üres string kezdőértékadás
Ha egy std::string típusú változónak nem adunk kezdőértéket, akkor is üres string lesz az értéke. Ez a két utasítás tehát ugyanazt a kezdőértékadást jelenti:
std::string variable1;
std::string variable2 = "";Miért fontos kezdőértéket adni a változóknak?
A függvények blokkjában (beleértve a main függvényt is) létrehozott változók (lokális változók) értéke nem lesz automatikusan nulla vagy nullával egyenértékű, hanem ha nem adunk nekik kezdőértéket, akkor valamilyen memóriaszemét (angolul garbage value) lesz az értékük, egy olyan adat, ami addig a számítógép memóriájának azon a részén volt, ami ki lett jelölve az adott változó értékének tárolására (pl. az előzőleg futó programok által feldolgozott adatok), látszólag egy véletlenszerű érték, ami egyébként sok esetben lehet hogy nulla. (Véletlenszám generáláshoz persze ez nem jó módszer, mert biztosan nem eredményezne véletlenszerű eloszlást).
Ez egyrészt akár hibához is vezethet, mert lehet, hogy ily módon az egyik változónak olyan értéke lesz, aminek a kezelésére a program nincs felkészítve (pl. képzeljük el, hogy valamilyen elemszám tárolására használt változó értéke -37689 lenne), másrészt előfordulhat, hogy a program ugyanarra a bemenetre más kimenetet produkál (anélkül, hogy ezt elvárnánk tőle, mondjuk véletlenszám generálásnál ez lehet elvárás).
- learncpp.com - variable assignment and initialization
- learncpp.com - uninitialized variables and undefined behaviour
- isocpp.org - always initialize
- cppreference.com - uninitialized scalar
- stackoverflow.com - why is using an uninitialized variable undefined behavior
- Jason Turner - Why Initialization Matters (videó)
Érdekességképp kiírathatjuk egy olyan változó értékét, aminek nem adtunk kezdőértéket, hogy megnézzük, hogy néz ki, ha egy változónak memóriaszemét az értéke.
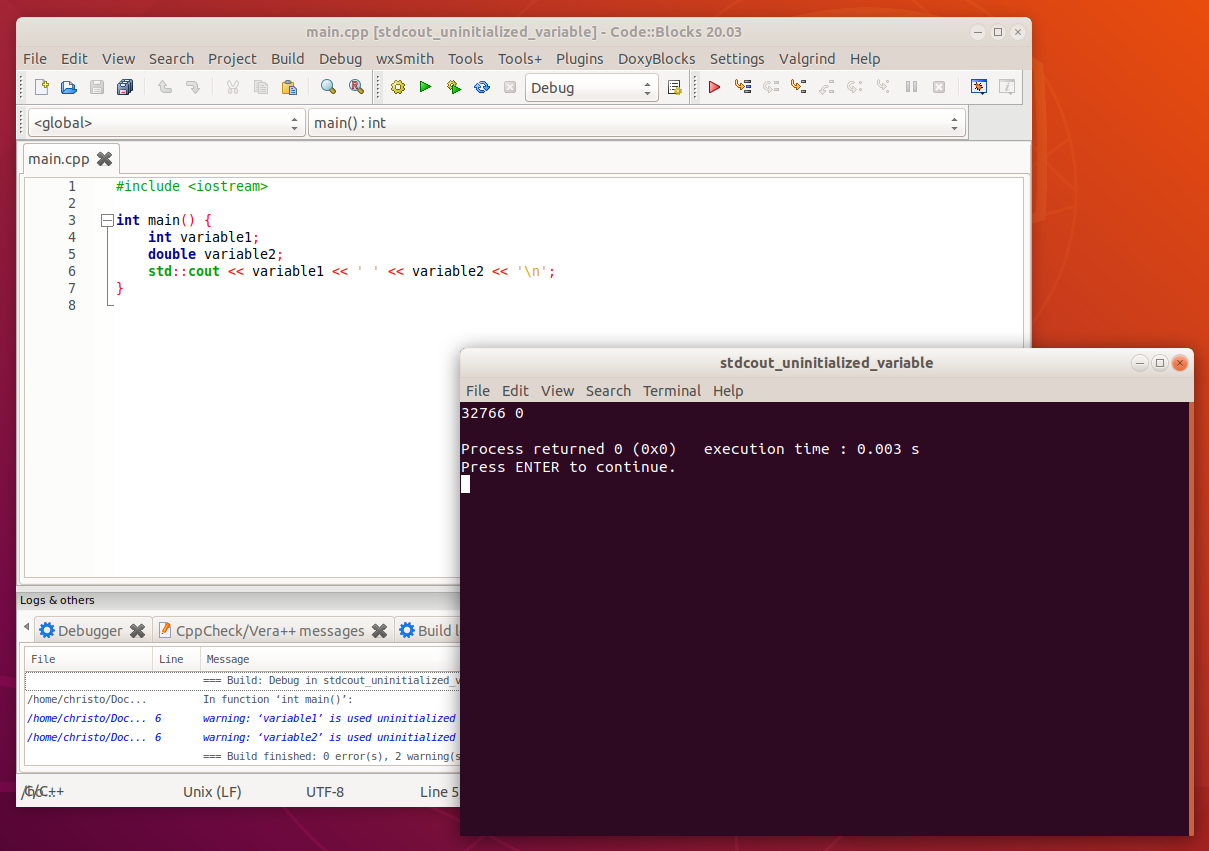
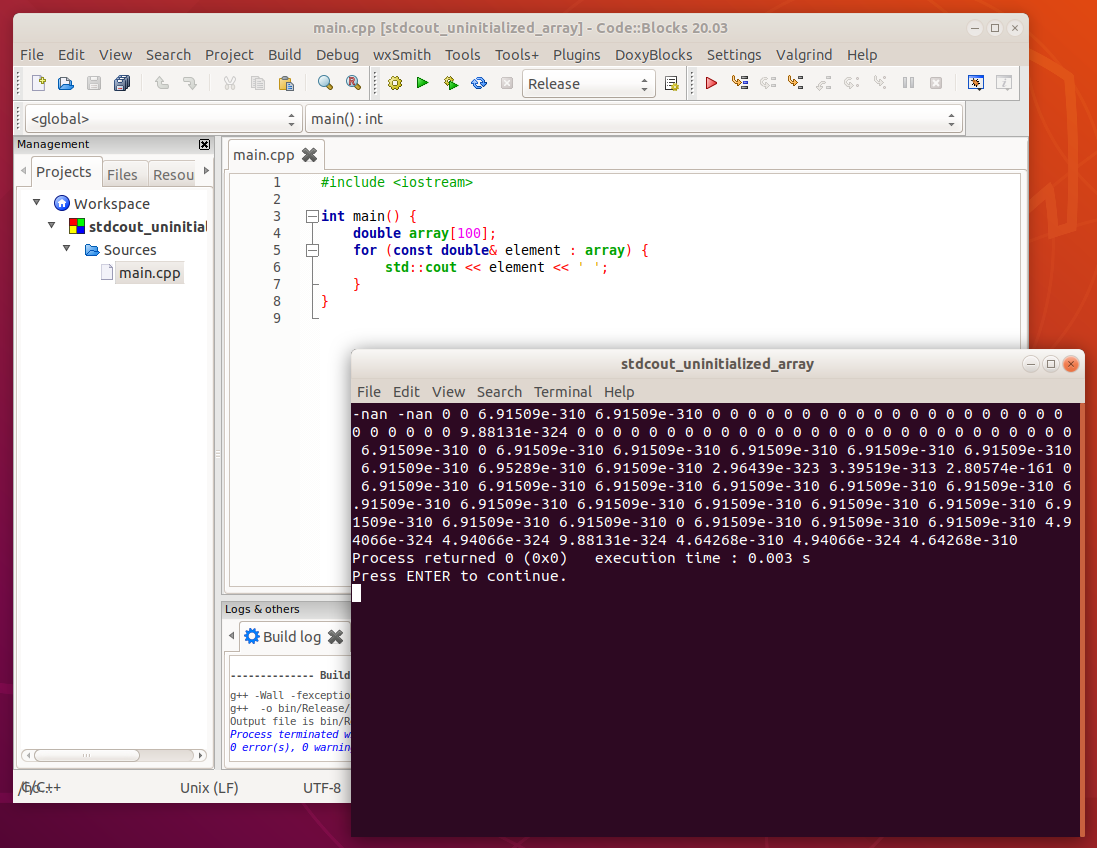
Ha csak 1-2 nem inicializált változó értékét íratjuk ki, akkor viszont könnyen lehet, hogy 0 lesz az értékük. Persze macerás lenne mondjuk 100 változót létrehozni csak emiatt, úgyhogy most ennek a példának a kedvéért egy 100 elemű tömböt hozunk létre, ami olyan, mintha 100 darab változót hoztunk volna létre. Itt most egyelőre nem a forráskód a lényeg, a tömböket későbbi tananyagrészben tárgyaljuk, hanem hogy el tudjuk képzelni, hogy milyen értéke van a nem inicializált változóknak.
Pl. double típus esetén:
Pl. char típus esetén:
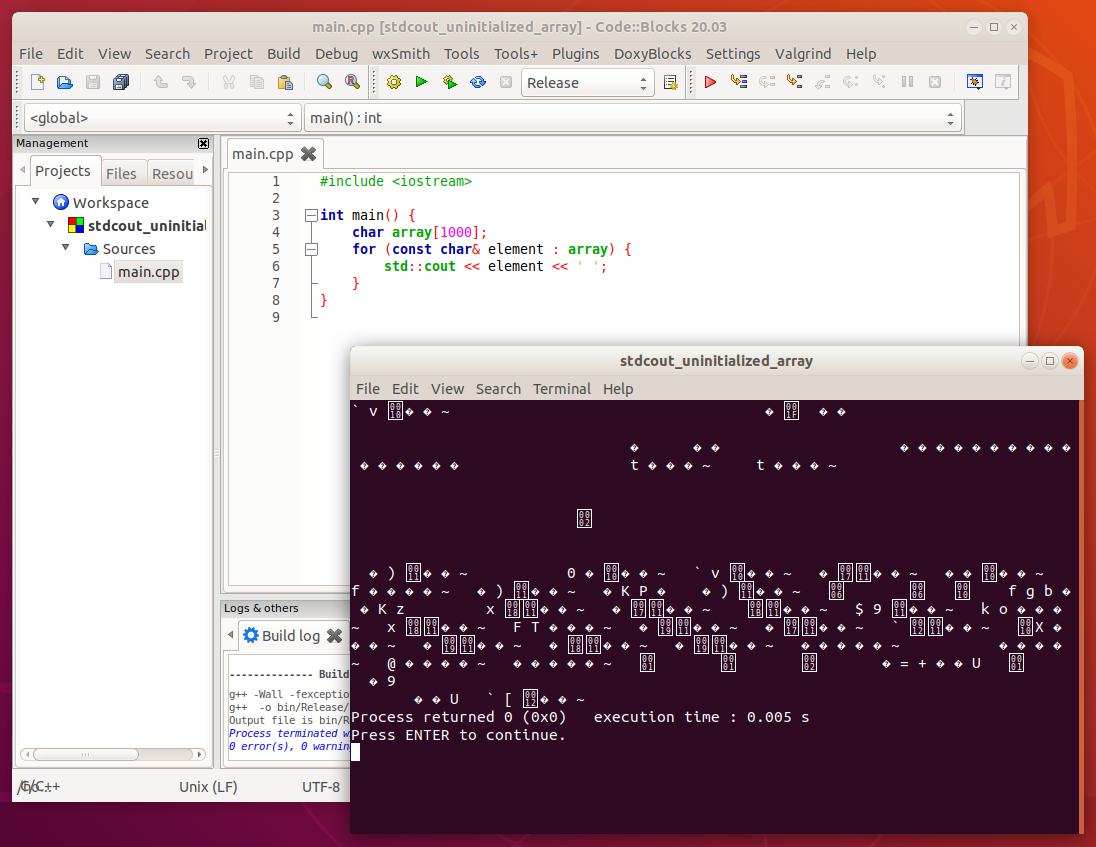
Azért nem látszódik sok karakter, mert a char típusban nem csak látható karaktereket lehet tárolni, hanem egyéb speciális karaktereket is.
Akkor érdemes egy változót létrehozni, amikor értelmes kezdőértéket tudunk neki adni, vagy tudjuk használni
A C nyelvben a C90 és azt megelőző szabvány szerinti kódokban a változókat egy blokk elején kellett létrehozni. A C++ nyelvben (illetve a C nyelvben a C99-es szabványtól) egy blokk bármelyik utasításaként létrehozhatunk változókat.
Lehetőség szerint egy változót akkor érdemes létrehozni, amikor ténylegesen használni fogjuk. Például ha egy változónak parancssorból vagy fájlból kérjük be az értékét, akkor a változót a bekérésre vonatkozó utasítás előtt érdemes létrehozni.
Ha egy blokk elején hozunk létre egy változót, de csak későbbi utasításban használjuk, vagy adunk neki kezdőértéket, akkor előfordulhat, hogy valaki úgy módosítja majd egyszer a forráskódot, hogy ez a változó mégiscsak használva legyen.
- isocpp.org - declare near first use
- isocpp.org - don't introduce a variable or constant before you need to use it
- isocpp.org - don't declare a variable until you have a value to initialize it with
- the deep blue c++ - define variables as close as possible where they are used
- Jason Turner - variables should be declared as late as possible
Alapvető műveletek változókkal
Jókat lehetne azon vitatkozni, hogy melyik legalapvetőbb műveletről érdemes előbb írni, pl. miért legyen szó arról, hogy hogyan kell kiíratni egy változó értékét, ameddig nem is végeztünk vele semmilyen műveletet, csak kezdőértéket adtunk neki, vagy mi értelme bármilyen műveletet végezni egy változóval, ha a végeredményt nem íratjuk ki. Bár úgyis lesz néhány példaprogram ennek a tananyagrésznek a végén, amiben lesz bekérés is, kiíratás is, meg egyéb művelet is, a változók értékének a kiíratását venném előre, mert a további műveleteket szemléletesebben be lehet mutatni ennek ismeretében.
Változók értékeinek kiíratása
(a standard outputra, alapesetben a parancssorba)
Hasonlóan a Hello Worldös példához, a változók értékének a kiíratásához is std::cout-ot és << operátorokat használunk.
A leggyakrabban használt típusú (char, int, double, std::string) változók aktuális értékét például ezzel az utasítással írathatjuk ki:
std::cout << valtozo_neve << '\n';Általában szoktunk a kiírt érték elé tenni valamilyen szöveget, amiben tájékoztatjuk a felhasználót arról, hogy minek az értékét írtuk ki, illetve szoktunk mögé tenni egy újsor karaktert vagy egy szóközt, hogy a következőleg kiírt dolog ne íródjon egybe a változó értékével.
(A felhasználó jó eséllyel nem fogja látni a forráskódot, így a változók nevei nem biztos, hogy különösebb jelentéstartalommal bírnának a felhasználó számára. A tananyagban lesznek olyan példák, ahol ezt nem tartjuk be, de ez a tananyag nyilván nem is a felhasználóknak szól.)
std::cout << "variable1 nevu valtozo erteke: " << variable1 << '\n';Ne felejtsünk el a változó értéke elé kiírt szöveg végére egy szóközt (vagy esetleg egyéb elválasztó jelet) tenni, hogy ne íródjon egybe a szöveg és a változó értéke.
Ha egyszerre több változó értékét szeretnénk kiíratni, akkor tegyünk közéjük szóközt, esetleg tabulátort, vagy írjuk őket külön sorba, hogy a két érték ne legyen íródjon egybe.
Két változó értékének kiíratása szóközzel elválasztva:
std::cout << "variable2 erteke: " << variable2 << ' ' << "variable3 erteke: " << variable3 << '\n';Két változó értékének kiíratása tabulátorral elválasztva:
std::cout << "variable2 erteke: " << variable2 << '\t' << "variable3 erteke: " << variable3 << '\n';Két változó értékének kiíratása külön sorba:
std::cout << "variable2 erteke: " << variable2 << '\n'
<< "variable3 erteke: " << variable3 << '\n';Ugyanezt akár így is írhatjuk:
std::cout << "variable2 erteke: " << variable2 << '\n';
std::cout << "variable3 erteke: " << variable3 << '\n';Értékadás
(angolul assignment), esetleg hozzárendelésnek is szokták nevezni
Egy már korábban létrehozott változó értékének megváltoztatása értékadó (angolul assignment) operátorokkal. Az értékadó operátorok listája itt található, de itt most csak a legegyszerűbbeket nézzük meg.
Valójában az egy darab egyenlőségjel operátort szokták értékadó, esetleg hozzárendelő (angolul assignment) operátornak nevezni, a +=, -=, *=, /=, és hasonló operátorokat compound assignment operátoroknak nevezik.
Hasonló kifejezéseket írhatunk az egyenlőségjel jobb oldalára, mint a kezdőértékadásnál, leszámítva persze a kerek- és kapcsos zárójeles inicializálást.
Példák értékadásra int típusú változók esetén (ezen példák esetén feltételezzük, hogy a variable1, variable2, satöbbi változókat int típusúként létrehoztuk ezen utasítások előtt):
variable1 = 128;variable2 = 0;Az értékül adott kifejezés nem csak egy literálból állhat, más változók értékeit is fel lehet használni az egyenlőségjel jobb oldalán szereplő kifejezésben.
variable3 = variable1 + variable2;Az egyenlőségjel jobb oldalán szereplő kifejezésbe nem csak egyszerű matematikai kifejezéseket írhatunk, hanem egyéb dolgokat is (pl. egy függvényhívást, ami visszaad valamilyen értéket), a lényeg, hogy a teljes kifejezés típusa egyező legyen az egyenlőségjel bal oldalán lévő változó típusával, vagy legalább automatikusan átkonvertálható legyen arra (ez utóbbiról részletes tananyagrész fog szólni).
Például egy std::string típusú változó értékének egy részszövegét a substr tagfüggvénnyel kaphatjuk meg. A példában a 7. karaktertől kezdődően (mivel a 0 felel meg a első karakternek, így a 6 a 7. karaktert jelenti) 7 karaktert ad vissza a substr tagfüggvény.
#include <iostream>
#include <string>
int main() {
std::string str_example = "Hello World!\n";
str_example = str_example.substr(6,7);
std::cout << str_example;
}Itt most épp értékadással kapcsolatos példáról volt szó, de ezt a példát természetesen lehetne egyszerűbben is írni, ha a tagfüggvényes kifejezés eredményét nem adnánk értékül a változónak, hanem azonnal kiíratnánk:
std::string str_example = "Hello World!\n";
std::cout << str_example.substr(6,7);Sőt, akár ilyet is lehetne csinálni, bár nyilván nem lenne túl sok értelme, mert akkor ennyi erővel már a "World!\n" sztring literált is kiírathatnánk egyből.
std::cout << std::string("Hello World!\n").substr(6,7);Hozzáadás (angolul addition assignment) a += operátorral. A variable4 eddigi értékéhez hozzáadjuk a variable5 értékét. Ezen két utasítás ugyanazt eredményezi:
variable4 += variable5;variable4 = variable4 + variable5;Hozzászorzás (angolul multiplication assignment) a *= operátorral. A variable6 eddigi értékét megszorozzuk tízzel. Ezen két utasítást ugyanazt eredményezi:
variable6 *= 10;variable6 = variable6 * 10;Egy utasításban egyszerre több változónak is adhatjuk ugyanazt az értéket. Ezt azért tehetjük meg, mert a C++ nyelvben egy utasítás nem csak utasítás, hanem kifejezés is egyben, vagyis van valamilyen értéke.
variable7 = variable8 = variable9;Ezen utasítást követően a variable4 és variable5 nevű változókba bemásolódik a variable6 változó értéke. Vagyis az egyetlen utasításban elhelyezett több értékadás jobbról balra értékelődik ki (erre szokták azt a kifejezést használni, hogy jobbról köt, vagy jobbról asszociatív).
Ha meg akarjuk nézni, hogy melyik operátor értékelődik ki jobbról balra vagy balról jobbra, például ebben a táblázatban megtaláljuk.
A compound assignment operátorokkal viszont ezt nem tehetjük meg, a következő utasítás fordítási hibát okoz:
//error
variable10 *= 3 += 4;Üres string értékadás
A string.clear() tafgüggvény használata hatékonyabb, mint ha operator=-vel adnánk üres stringet értékül. Tehát ehelyett:
std::string example = "something";
//statements
example = "";Használjuk inkább ezt:
std::string example = "something";
//statements
example.clear();Ennek a hátteréről bővebben:
Változók értékének a bekérése a felhasználótól
(a standard inputról, alapesetben a parancssorból)
Ha azt szeretnénk, hogy egy parancssoros program futtatásakor a felhasználó begépelhesse a bemenő adatokat, akkor ehhez a C++ nyelvben általában std::cin-t vagy szóközt tartalmazó szövegek esetén getline-t szoktunk használni.
Ha az #include <iostream> preprocesszor direktíva szerepel egy forrásfájl elején, akkor abban a forrásfájlban használhatjuk az std::cin-t. Például ha korábban létrehoztunk mondjuk egy int típusú (vagy akár más típusú is lehetne) variable1 nevű változót, akkor ezzel az utasítással kérhetünk be a parancssorból értéket neki:
std::cin >> variable1;Érdemes persze kiíratni valamilyen arra vonatkozó szöveget, hogy milyen adatot vár a program a felhasználótól. Ennél a példánál természetesen feltételezzük, hogy egy std::string típusú username nevű változó ezen utasítások előtt már létre lett hozva:
std::cout << "Kerem adja meg felhasznalonevet:\n";
std::cin >> username;Ha a program futása ehhez az utasításhoz ér, a felhasználó valami ilyesmit fog majd látni:
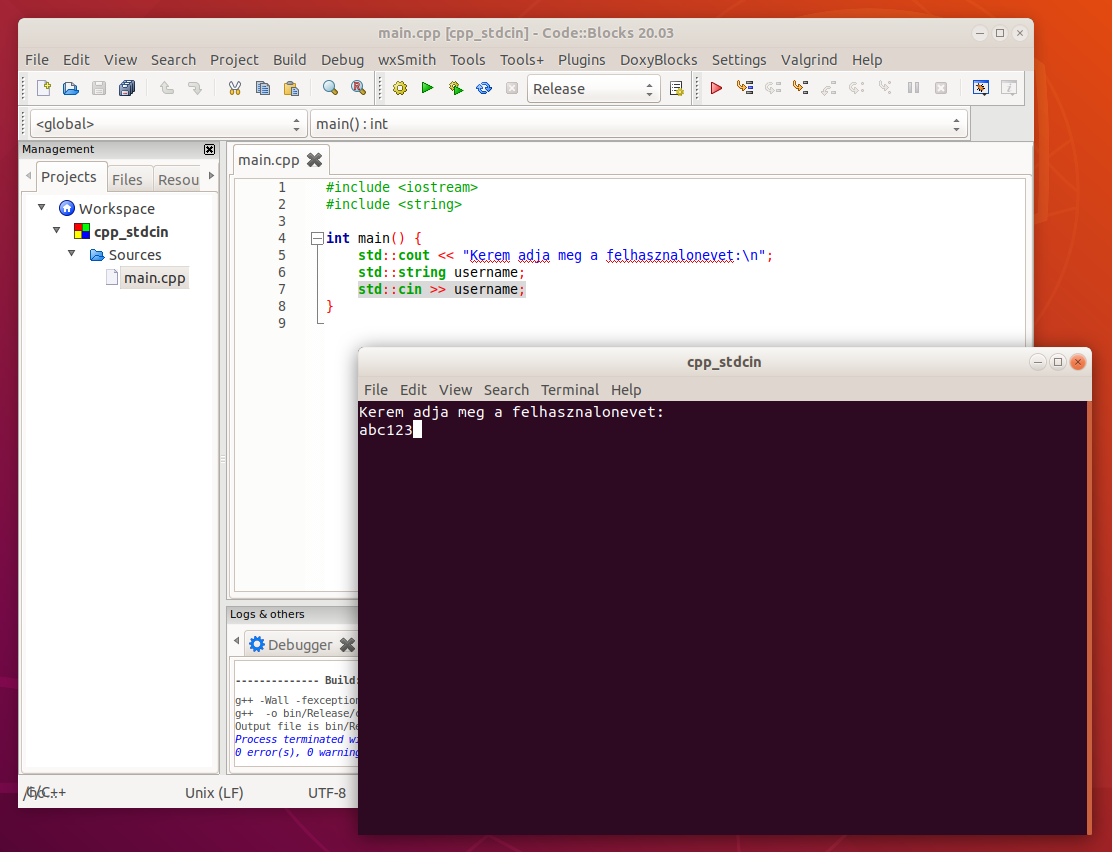
A forráskódot természetesen jó eséllyel nem fogja látni a felhasználó. Ezen a screenshoton csak azért szerepel, hogy könnyen össze lehessen hasonlítani a kódot és a futtatás eredményét.
A >> operátor (amit angolul extraction operatornak neveznek) csak az első szóközig olvassa be a felhasználó által beírt értéket. Ez sok esetben megfelelő, viszont ha például a felhasználó teljes nevét szeretnénk parancssorból bekérni, akkor abban jó eséllyel szerepelhet szóköz.
Amelyik forrásfájlban szerepel az #include <string> preprocesszor utasítás, ott használhatjuk a getline függvényt. Például egy std::string típusú fullname nevű változóba így tudunk szóközt is tartalmazó szöveget parancssorból bekérni:
std::cout << "Kerem adja meg a teljes nevet:\n";
getline(std::cin, fullname);Fontos, hogy ezzel a getline függvénnyel csak std::string típusú változóknak kérhetünk be értéket a parancssorból. Ezt a getline függvényt std::getline néven is elérjük, tehát a fenti kódrészlet második sorát így is lehetne írni: std::getline(std::cin, fullname);
Létezik viszont egy másik getline függvény, az std::cin.getline, amit az #include <cstring> preprocesszor utasítással tehetünk elérhetővé, de azt nem std::stringekhez, hanem karaktertömbökhoz használhatjuk, amire majd a tömbök tananyagrészt követően nézünk példát. Itt most csak azért említettem meg, hogy érdemes odafigyelni, hogy ne keverjük össze a kettőt (például ha internetről ollózgatunk össze kódrészleteket, akkor ez könnyen előfordulhat).
Ha mindkét módszert vegyesen szeretnénk használni a forráskódban (tehát a std::cin >> valtozo; és a getline(std::cin, valtozo); utasításokat), akkor viszont egyéb teendőkre is szükség van, hogy a program helyesen működjön.
Csak akkor van gond, ha egy std::cin >> valtozo; utasítás után egy getline(std::cin, valtozo); utasítás szerepel, fordított esetben nem.
Az input bufferről dióhéjban
A felhasználó által a parancssorba begépelt értékek nem közvetlenül, egyetlen lépésben másolódnak be azokba a változókba, amikbe bekértük őket. Ez például azért van így, mert ha sok adatot kell feldolgozni, akkor gyorsabb először az egész bemenetet bemásolni a memóriának egy külön erre a célra fenntartott részére (ezt nevezik input buffernek), és utána egyessével áthelyezgetni őket a változókba (illetve tömbökbe és objektumokba).
Az std::cin >> username; utasítás bennehagy az input bufferben egy sorvége jelet, ami egy újabb std::cin >> valtozo; utasítás esetén nem okoz gondot, viszont a getline(std::cin, fullname); utasítás bemenetként értelmezi ezt az egyetlen sorvége jelet is, így a fullname változónak egy sorvége jel adódik értékül, ha előtte egy std::cin >> valtozo; utasítás szerepel.
Ahogy a screenshoton is látható, az első bekérésnél (std::cin >> username;) a felhasználó begépelheti a username változónak szánt értéket, a második bekérés viszont nem történik meg, a program továbbugrik. (Ha lenne utána mégegy getline-os bekérés, az már működne, mivel a getline eltávolítja a sorvége jelet az input bufferből).
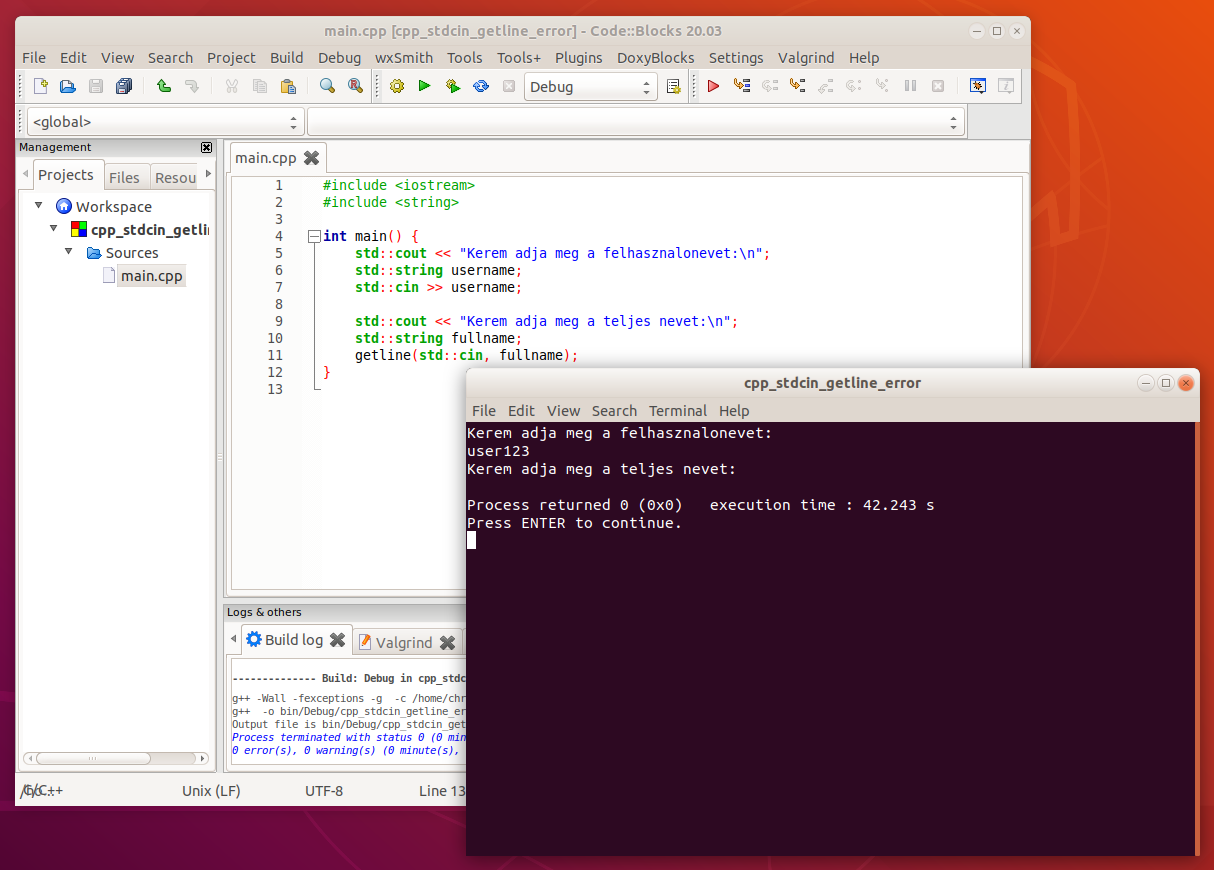
Ahhoz, hogy ezt elkerüljük, törölnünk kell az input buffer tartalmát. Ezt a std::cin objektum ignore tagfüggvényével tehetjük meg. Ennek a tagfüggvénynek két bemenő adatot (úgynevezett aktuális paramétert, más néven argumentumot) adhatunk meg. Az első paraméter, hogy hány karaktert töröljön az input bufferből, a második paraméter pedig egy tetszőleges karakter, aminek az első előfordulásáig törlődik az input buffer tartalma (ezen példa esetén ez értelemszerűen az újsor karakter). Az első paraméterként egy konkrét szám helyett érdemes az input buffer maximális méretét megadni (amit a std::numeric_limits osztály max nevű tagfüggvénnyel tehetünk meg (std::streamsize típusparaméterrel), mely tagfüggvényt az #include <limits> preprocesszor utasításnak köszönhetően érhetjük el), akkor bármekkora is legyen az input buffer tartalma, törölve lesz az összes karakter a második paraméterben megadott karakter első előfordulásáig:
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');Természetesen most még nem kell érteni, hogy ebben az utasításban az egyes szintaktikai elemek pontosan mire valók, osztályokról és templatekről majd későbbi tananyagrészben lesz szó.
Ez nyilván nem egy teljes példaprogram, így önmagában nem sok értelme van, mert csak bekér két értéket a felhasználótól, és azokkal nem végez semmilyen műveletet.
//getline after std::cin>>
#include <iostream>
#include <string>
#include <limits>
int main() {
std::cout << "Kerem adja meg a felhasznalonevet:\n";
std::string username;
std::cin >> username;
//delete the value of input buffer
//to correctly use getline after std::cin>>variable_name
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
std::cout << "Kerem adja meg a teljes nevet:\n";
std::string fullname;
getline(std::cin, fullname);
}Mások kódjában esetleg találkozhatunk olyan megoldással, amiben a std::cin.ignore első paramétereként egy konkrét szám (pl. 1000) van megadva. Ez persze sok esetben beválhat, de nem árt, ha a program tudja azokat a ritka eseteket is kezelni, amikor valahogy mégis több karakter kerül az input bufferbe, mint egy konkrétan megadott számérték, pl. 1000.
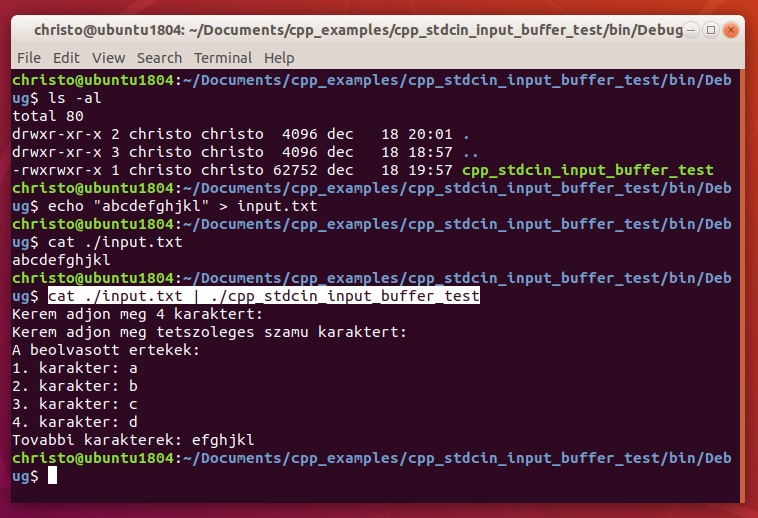
Az input buffer működésének megértésében segíthet a következő példaprogram, amelyben értéket kérünk be 4 karakter típusú változónak, és egy std::string típusú változónak.
//input buffer test
#include <iostream>
#include <string>
int main() {
std::cout << "Kerem adjon meg 4 karaktert:\n";
char ch1{}, ch2{}, ch3{}, ch4{};
std::cin >> ch1 >> ch2 >> ch3 >> ch4;
std::cout << "Kerem adjon meg tetszoleges szamu karaktert:\n";
std::string str;
std::cin >> str;
std::cout << "A beolvasott ertekek:\n";
std::cout << "1. karakter: " << ch1 << '\n';
std::cout << "2. karakter: " << ch2 << '\n';
std::cout << "3. karakter: " << ch3 << '\n';
std::cout << "4. karakter: " << ch4 << '\n';
std::cout << "Tovabbi karakterek: " << str << '\n';
}Amikor a felhasználó az értékeket megadja, célszerű lenne minden megadott érték után az enter billentyűt megnyomni a billentyűzeten, így jól látszik, hogy melyik az első megadott érték, melyik a második, satöbbi.
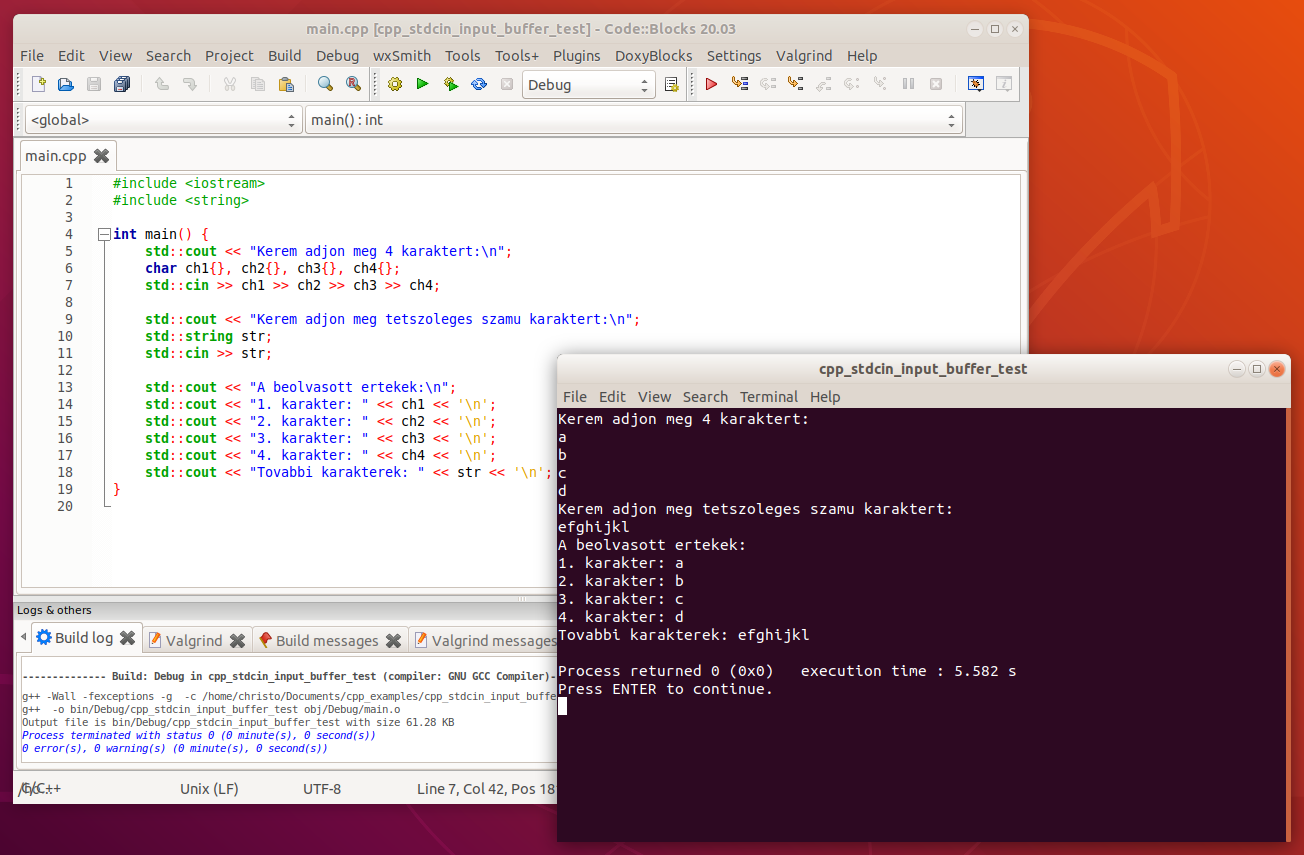
A felhasználó szóközökkel elválasztva is megadhatja az egyes értékeket, a beolvasás akkor is jól fog működni, leszámítva persze azt, hogy a std::cin >> valtozo; utasítás az első szóközig olvas be, így ha a további karakterek közé is szóközt tesz a felhasználó, akkor azok közül csak egy lesz beolvasva. A getline függvénnyel meg lehetne oldani, hogy az összes további karakter a szóközökkel együtt értékül legyen adva az str nevű változónak, de itt ebben a példában most nem ez a lényeg.
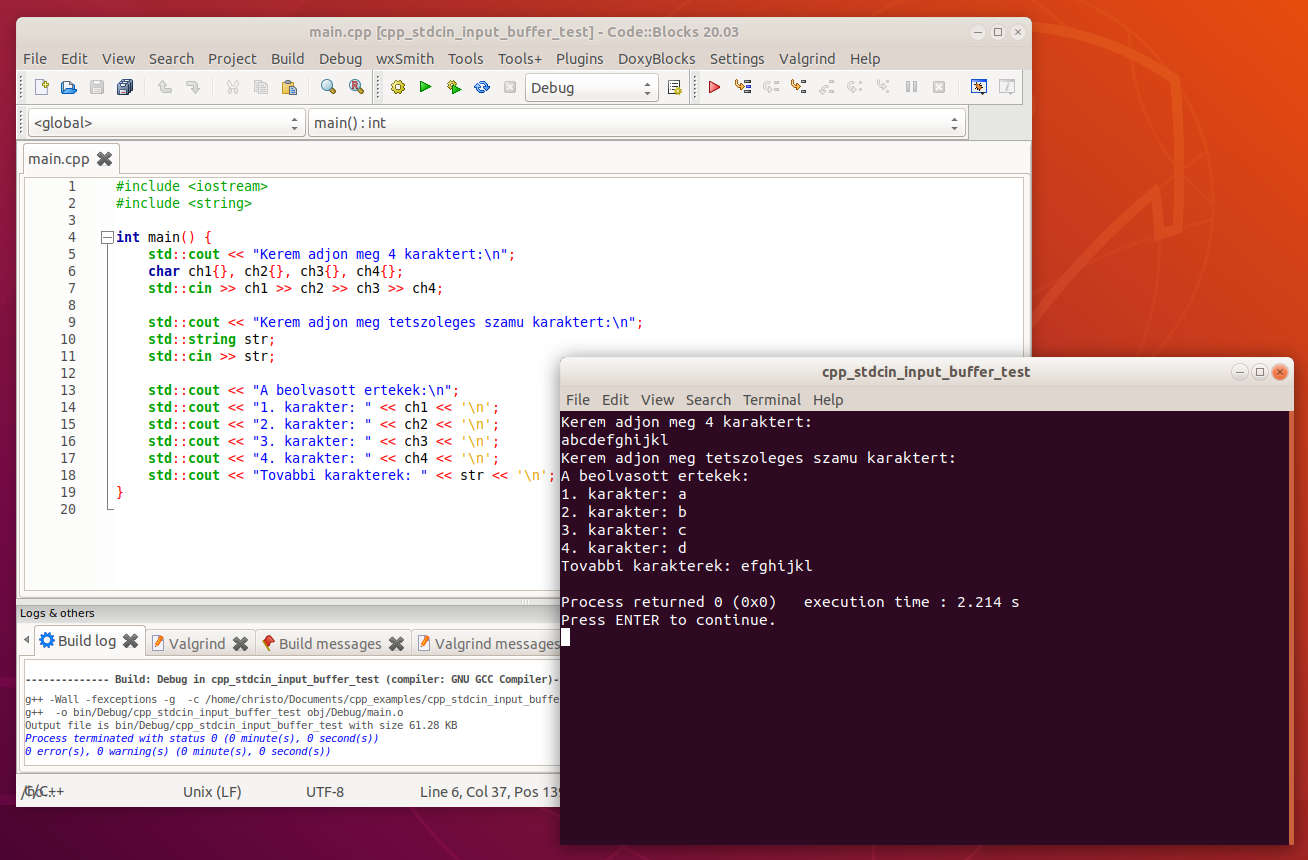
A felhasználó akár egybe is írhatja a teljes bemenetet, az értékek akkor is a megfelelő változókba lesznek beolvasva.
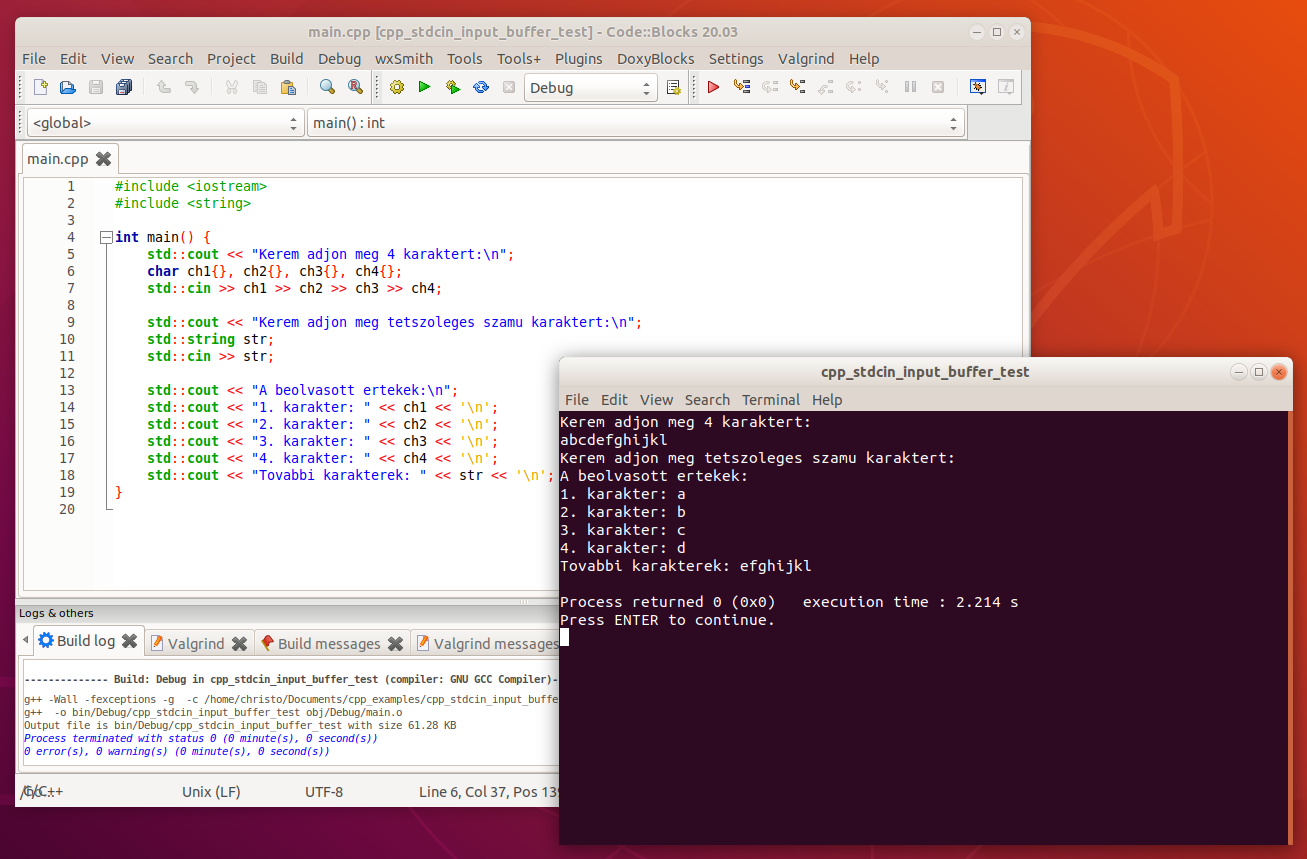
- stackoverflow.com - how does input buffer works in c++
- stackoverflow.com - how does extract operator works in c++
Standard input
Az std::cin a standard inputról olvas be. Ez alapesetben a felhasználó által begépelt értékeket jelenti, de akár fájlok tartalmát, esetleg más programok kimenetét is át lehet irányítani egy program bemenetére, és akkor az std::cin ezt az átirányított bemenetet fogja feldolgozni.
Ezen a screenshoton az látható, hogy egy input.txt nevű fájlba beleírjuk, hogy abcdefgjkl, majd kiíratjuk a parancssorba a fájl tartalmát a cat paranccsal, ezt követően pedig a cat parancs kimenetét (a fájl tartalmát) átirányítjuk az úgynevezett pipe segítségével a fenti példaprogram bemenetére. Ekkor a program ugyanúgy fog viselkedni, mintha csak a felhasználó írta volna be a program futtatása közben a fájlban található szöveget.
Hibás input
Természetesen attól függetlenül, hogy kiírunk egy arra vonatkozó üzenetet a programban, hogy itt most éppen egy egész számot vár a program, a felhasználó (akár véletlenül, akár szándékosan) begépelhet mást is, például betűket vagy egyéb írásjeleket.
Bár ez elég alapvető probléma, erre is későbbi tananyagrészben tudok csak kitérni, mivel a megoldások tartalmaznak elégazást, ciklust, esetleg függvénydefiníciót is.
Random generált szám, random generált string értékül adása változóknak
Ezekről későbbi tananyagrészekben lesz szó.
További műveletek változókkal
Változókkal kapcsolatos egyszerű műveletekről a gyakori műveletek tananyagrészben lesz szó.
Konstansok
const
Ebben a tananyagban a konstans szót önmagában használva a const típusminősítővel ellátott változókra értjük.
Szokták a const típusminősítővel ellátott változókat konstans változónak (angolul constant variable) is nevezni, bár ez az elnevezés kicsit megtévesztő, mivel a konstansok pont abban különböznek a változóktól, hogy az értékük a program futása során nem változhat meg, másképp fogalmazva ameddig léteznek, végig a kezdőértékük marad az értékük.
Egy konstanst a programozásban akkor használunk, ha egy adatot a forráskódban többször is fel szeretnénk használni (pl. többször ki szeretnénk íratni vagy többször szeretnénk használni valamilyen kifejezésben/műveletben), de nem szeretnénk, hogy ez az adat a program futása során megváltozzon.
Érdemes kihangsúlyozni, hogy a konstansokra ne úgy tekintsünk, hogy bizonyos változók értékét a programozó nem változtathatja meg, hanem hogy a programozó nem szeretné, ha bizonyos változók értéke megváltozna, és ha mondjuk egy sok-sok kódsorból álló programban valaki mégis megpróbálná megváltoztatni egy ilyen változó értékét, akkor fordítási hibát kap. Másrészt ha jelezzük a fordítónak, hogy egy változó értéke nem fog megváltozni, akkor a fordító tud optimalizálni (pl. valamivel gyorsabb lehet ettől a program, vagy kevesebb memóriát foglalhat).
A konstansokat ugyanúgy létre kell hozni a használatuk előtt, mint a változókat, viszont a létrehozáskor kötelező kezdőértéket adni nekik, különben fordítási hibát kapunk. A típusuk is ugyanaz lehet, mint a változóknak.
#include <iostream>
#include <string>
int main() {
const int constant1 = 42;
const double constant2 {3.14};
const std::string constant3 = {"Hello World!"};
std::cout << "constant1 erteke: " << constant1 << '\n';
std::cout << "constant2 erteke: " << constant2 << '\n';
std::cout << "constant3 erteke: " << constant3 << '\n';
}//error
const int constant1;//error
const int constant1 = 1234567890;
constant1 = 2345678901;Azt is érdemes kihangsúlyozni, hogy C++ nyelvben const típusminősítővel ellátott változó kaphat olyan kezdőértéket, ami nem konstans változóból származik és nem derül ki fordítási időben. A lényeg csak az, hogy a konstans értéke a kezdőértékadást követően nem változhat meg.
//initialize const with non-const value
#include <iostream>
int main() {
int variable1;
std::cout << "Please enter an integer value:\n";
std::cin >> variable1;
const int variable2 = variable1;
std::cout << variable2 << '\n';
}constexpr
Ha azt szeretnénk, hogy egy változó csak olyan értéket kaphasson, ami fordítási időben kiderül, akkor használhatjuk a constexpr kulcsszót. Ez például fordítási hibát okoz:
//error, constexpr value must be a compile time value
#include <iostream>
int main() {
int variable1;
std::cout << "Please enter an integer value:\n";
std::cin >> variable1;
constexpr int variable2 = variable1;
std::cout << variable2 << '\n';
}A const kulcsszót egyébként a C++ nyelvben számtalan más kontextusban is lehet használni, például tömbök, függvények paramáterátadása (úgynevezett konstans referenciák), objektumok, pointerek esetén.
Illetve előfordulhat, hogy más tananyagok a konstans kifejezést literálokra és temporálisokra is használják.
A konstans szó gyakori szinonímája az immutable, amivel főként akkor találkozhatunk, amikor osztályokról, objektumokról esik szó.
- isocpp.org - prefer immutable data to mutable data
- Jason Turner - const as much as possible
- isocpp.org - use conventional const notation
Preprocesszor makrók
A C nyelvben eleinte nem léteztek konstansok (const típusminősítővel ellátott változók). Helyettük preprocesszor makrókat használtak, ami a mai napig elterjedt szokás és néha C++ nyelven írt forráskódban is találkozhatunk velük. Bár preprocesszor makrók használata C++ nyelvben kerülendő, mivel mások által írt kódban találkozhatunk velük, így azért érdemes tisztában lenni, hogyan működnek.
Például ha a #define N 5 preprocesszor makró szerepel a kódunkban (jellemzően az include direktívák alá szokták tenni a makrókat), akkor a kódunkban ahol csak leírtuk, hogy N, az még a tényleges fordítás megkezdése előtt ki lesz cserélve 5-re (ha az N egy több karakterből álló szó része (pl. NUMBER), akkor azon belül a szavon belül nem lesz kicserélve 5-re).
#include <iostream>
#define N 5
int main() {
std::cout << N << '\n';
std::cout << N*2 << '\n';
}Előre definiált makrók
Angolul predefined macros. Olyan preprocesszor makrók, amik vagy benne vannak a C++ nyelvben alapból, vagy pedig a C++ standard library valamelyik header fájljának includeolásával érhetjük el őket.
Például a __cplusplus makró megadja, hogy milyen verziójú C++-t használunk.
#include <iostream>
int main() {
std::cout << "Version of C++ standard in this program: " << __cplusplus << '\n';
}Ezt a kódot különféle C++ online fordítókkal is érdemes kipróbálni, például a wandbox.org vagy rextester.com oldalakon.
Egy másik példában a __DATE__ és __TIME__ makrókkal a dátumot és a pontos időt kaphatjuk meg:
#include <iostream>
int main() {
std::cout << "Current date: " << __DATE__ << '\n';
std::cout << "Current time: " << __TIME__ << '\n';
}Az első program tananyagrészben szó esett az EXIT_SUCCESS és EXIT_FAILURE előre definiált makrókról.
További előre definiált makrók:
- gcc.gnu.org - predefined macros
- clang.llvm.org - buildin macros
- docs.microsoft.com - predefined macros
- blog.kowalczyk.info - Guide to predefined macros in C++ compilers (gcc, clang, msvc)
Literálok
A literálok forráskódban szereplő adatok (konkrét értékek), melyekkel a program dolgozik, melyeket a program feldolgoz.
Például:
std::cout << "karakter literal: " << 'a' << '\n';
std::cout << "egesz szam literal: " << 42 << '\n';
std::cout << "valos szam literal: " << 3.14 << '\n';Természetesen a '\n' is karakter literál a fenti példákban.
Az idézőjelek közé tett szövegeket nevezzük string literáloknak.
std::cout << "string literal: " << "12345abcdef\n";A "string literal: " is egy string literál a fenti példában, nem csak a "12345abcdef\n".
Inicializáláshoz és értékadáshoz is használhatunk literálokat, bár ezek elméletben is csak az őket tartalmazó utasítás végrehajtásakor léteznek literálként, ezért inkább úgy tekintünk rájuk, mint változók kezdőértéke, vagy értéke.
int variable1 {0};
variable1 = -256;Fontos megjegyezni, hogy a literáloknak is van típusa. Erről információkat itt találhatunk:
- alaptípusok jellemzői - típusmódosítók a literálokban
- stringek, stringműveletek (alapvető tudnivalóknál az első kódpéldák)
Egyéb tananyagok a literálokról:
- cplusplus.com - literals
- cppreference.com - character literal
- cppreference.com - integer literal
- cppreference.com - floating literal
- cppreference.com - string literal
- cppreference.com - user literal
Kifejezések (értéke/típusa)
Fontos megjegyezni, hogy minden kifejezésnek van értéke és típusa.
Példák:
- 5.1 + 1 kifejezés értéke 6.1, típusa doube
- int a = 6.1; kifejezés értéke 6, típusa int
- 4 kifejezés értéke 4, típusa int
- 5.1 kifejezés értéke 5.1, típusa double
Temporálisok
A temporálisok (angolul anonymus object) olyan értékek, amelyen változókkal és/vagy literálokkal végzett műveletek eredményei, részeredményei.
std::cout << "2 + 2 = " << 2 + 2 << '\n'; //
int a = 1, b = 2, c = 3, d = 4, e = 5;
std::cout << a + b + c + d + e;//
Példaprogram
Ebben a példaprogramban különböző változóknak kérünk be a felhasználótól értékeket, majd kiíratjuk a beolvasott eredményt.
Van benne olyan példa is, amikor egy std::cin >> variable; utasítást követően szerepel egy getline(std::cin, variable); utasítás. E kettő között ugyebár törölni kell az input buffer tartalmát, ahhoz, hogy a bekérés rendeltetésszerűen működjön.
//cpp example: variables, input, output
#include <iostream>
#include <string>
#include <limits>
int main() {
//input
std::cout << "Kerem adjon meg egy szokozt nem tartalmazo szoveget (pl. abcdef):\n";
std::string str_variable1;
std::cin >> str_variable1;
//delete the value of input buffer
//to correctly use getline after std::cin>>variable_name
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
std::cout << "Kerem adjon meg egy szokozoket is tartalmazo szoveget (pl. abc 123):\n";
std::string str_variable2;
getline(std::cin, str_variable2);
std::cout << "Kerem adjon meg egy egesz szamot (pl. -12345):\n";
int i_variable{};
std::cin >> i_variable;
std::cout << "Kerem adjon meg egy valos szamot (pl. -3.14):\n";
double d_variable{};
std::cin >> d_variable;
std::cout.put('\n');
//output
std::cout << "A beolvasott ertekek:\n";
std::cout << "string (szokozok nelkul): " << str_variable1 << '\n';
std::cout << "string (szokozoket megengedve): " << str_variable2 << '\n';
std::cout << "egesz szam: " << i_variable << '\n';
std::cout << "valos szam: " << d_variable << '\n';
}Fontos megjegyezni, hogy ez a program rosszul működik, ha a felhasználó például egy egész szám bekérésekor szöveges értéket ad meg. Ennek a megoldása egy későbbi tananyagrész témája:
Egyéb
Ne használjunk egyetlen változót többféle adat tárolásához. Például nehezebben áttekinthető, ha ugyanabban a változóban a program egyik részében valakinek az életkorát tároljuk, aztán a program másik részében pedig mondjuk egy irányítószámot.
Az operator<< és az operator>> globális függvény vagy tagfüggvény?
Az első program c. tananyagrészben volt szó arról, hogy az std::cout << "some text\n"; utasítást akár írhatnánk olyan formában ahogy általában a függvényhívásokat:
operator<<(std::cout, "some text\n");Ha változókat akarnánk így kiíratni, akkor ugyan a char vagy az std::string típus esetén működik, de pl. int és double típusok esetén fordítási hibát kapunk, mivel ilyen típusú paraméter esetén az operator<< tagfüggvényként lett definiálva, nem pedig globális függvényként (angolul free function).
char ch_example = 'a';
//free function:
operator<<(std::cout, ch_example);std::string str_example = "some text\n";
//free function:
operator<<(std::cout, str_example);int i_example = 128;
//member function:
std::cout.operator<<(i_example);double d_example = -3.14;
//member function:
std::cout.operator<<(d_example);Viszont kéne a kiíratás végére egy újsor karakter is, illetve ha több dolgot szeretnénk kiíratni, akkor közéjük szóközöket vagy tabulátorokat kéne tenni.
Tovább bonyolítja a helyzetet, hogy a karakterek (karakter literálok és char típusú változók) kiíratása tagfüggvénnyel nem működik megfelelően (egy karakter helyett a karakter ascii kódja íródik ki), ezért azt globális függvénnyel kell kiíratni, mint ahogy az std::stringeket.
int i_example = 128;
double d_example = 3.14;
std::cout.operator<<(i_example);
operator<<(std::cout, ' ');
std::cout.operator<<(d_example);
operator<<(std::cout, '\n');Az utóbbi 4 utasítást akár 1 utasításba is lehetne, írni, amit átlátni viszont nem egyszerű:
operator<<((operator<<(std::cout.operator<<(i_example),' ')).operator<<(d_example),'\n');Hasonló a helyzet az std::cin esetén is: char és std::string esetén operator>>(std::cin, variable_name), int és double esetén pedig std::cin.operator>>(variable_name).
Pont azért lettek kitalálva az operátorok, hogy ne kelljen a függvényhívás megszokott formájában írni őket.
Egyéb kapcsolódó tananyag
- learncpp.com - introduction to variables
- learncpp.com - const, constexpr, symbolic constants
- learncpp.com - literals
Előző tananyagrész: várakozás enter billentyű megnyomásáig
Következő tananyagrész: gyakori műveletek


