
Ebben a tananyagrészben arról lesz szó, hogyan tudjuk bizonyos utasítások végrehajtását feltételhez kötni.
Előző tananyagrész: alapvető típuskonverziók
Következő tananyagrész: switch-case, ternáris operátor
Tartalom
- if-else alapvető tudnivalók:
milyen kifejezéseket adhatunk meg feltételnek
logikai konverziók
if (variable_example == true) helyett if (variable_example)-t írjunk - 1. példa: abszolút érték
- 2. példa: páros vagy páratlan (==, != és || operátorok)
- 3. példa: random páros szám
- 4. példa: melyik szám nagyobb (if-elseif-else)
- 5. példa: centiméter/inch konvertálás
- 6. példa: ascii tábla (&& operátor)
- 7. példa: kisbetűsítés, nagybetűsítés
- 8. példa: függvények
- változók láthatósága: scope, variable shadowing, elrejtés
- hibalehetőségek: == és = operátor, yoda conditional, csellengő else
- egyéb:
true és false értékek kiíratása couttal
a bool típus méretéről
Alapvető tudnivalók
Nyilvánvalóan nem lenne olyan sokmindenre jó a programozás, ha a programjainkban csak értékeket bekérni, módosítani és kiíratni lehetne (erről szólt a változók, konstansok, literálok tananyagrész).
A programozás egyik leglényegesebb lehetősége, hogy egy program futtatásának különböző forgatókönyei is lehetnek, például attól függően, hogy a felhasználó mit csinál (milyen értékeket ad meg, hova kattint, stb), vagy attól függően, hogy mit tartalmaz egy fájl, vagy milyen értékeket tartalmaznak a programban szereplő változók.
Struktúrált programozási nyelvek
Az struktúrált programozási nyelvekben (a C++ is ezek közé tartozik) három alapvető vezérlési szerkezet segítségével (és ezek kombinációjával) alakíthatjuk az utasítások sorrendjét: rákövetkezés (szekvencia), feltételes elágazás vagy esetszétválasztás (szelekció), ciklus (iteráció, ismétléses vezérlés).
Az eddigi példaprogramjaink túlnyomó része csak szekvenciát tartalmazott, vagyis a forráskód minden utasítása olyan sorrendben hajtódott végre, ahogy a forráskódban szerepeltek.
A struktogramok vezérlési szerkezeteket szemléltető ábrák, melyeken jól látható a szekvencia és az elágazás közti különbség:

A szekvencia struktogramja
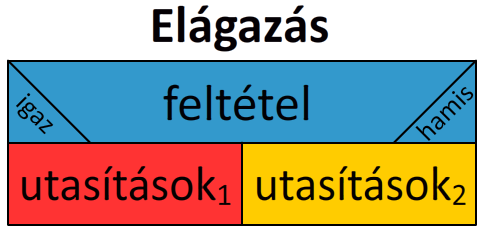
Az elágazás struktogramja
A folyamatábrák talán jobban szemléltetik az egyes vezérlési szerkezetek működését, viszont struktogramokkal viszonylag nagyobb kódrészletet lehet átláthatóbban ábrázolni, mint folyamatábrákkal.
A párhuzamos programozást támogató programnyelvekben szerepelhetnek egyéb vezérlési szerkezetek is, illetve a nem imperatív programozási nyelvekben (amikben nem használunk változókat) a fentiektől eltérőek a vezérlési szerkezetek (pl. a Haskell, Clean, OCaml nyelvekben), de ezekről ebben a tananyagban nem lesz szó.
Elágazások
if-else
Utasítások feltételhez kötésének legalapvetőbb módja az if-else elágazás. Segítségével megadhatjuk, hogy milyen utasítások hajtódjak végre akkor, ha egy általunk (a program forráskódjában) meghatározott feltétel (angolul condition) teljesül (másképp fogalmazva a megadott logikai kifejezés értéke igaz), illetve akkor, ha a feltétel nem teljesül (másképp fogalmazva a megadott logikai kifejezés értéke hamis). ó
Az if-else alapvető működését szemléltető kód (ez csak szemléltető kód, nem használható, fordítási hibát okoz):
if ( /*condition*/ ) {
//statements executed if the condition is true
} else {
//statements executed if the condition is false
}Egy if-else elágazásban vagy az if, vagy pedig az else blokkjában lévő utasítások biztosan lefutnak. Egyszerre mindkét blokk utasításai nem futhatnak le, és olyan sem történhet, hogy egyik blokk utasításai sem futnak le.
Az else blokk megadása opcionális, előfordul, hogy azt szeretnénk, hogy csak akkor hajtódjanak végre bizonyos utasítások, ha a megadott feltétel igaz, ha pedig hamis, akkor a vezérlés folytatódjon az elágazás után.
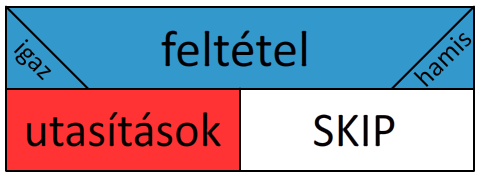 A struktogramokban a SKIP kifejezést használjuk egy elágazás valamely ágának kihagyására:
A struktogramokban a SKIP kifejezést használjuk egy elágazás valamely ágának kihagyására:
Az if és else blokkokba ugyanolyan utasításokat írhatunk, mint amiket például ezidáig a main függvény blokkjába írtunk.
Milyen kifejezéseket írhatunk a feltétel (/*condition*/ komment) helyére?
- jellemzően olyan logikai kifejezéseket, amikben változónevek és relációs jelek, esetleg literálok szerepelnek, például:
variable1 nevű változó értéke nagyobb-e mint nulla:
if (variable1 > 0) {
//statements
} else {
//statements
}Ekkor ha a variable1 nevű változó értéke nagyobb, mint 0, akkor az if ágban lévő utasítások fognak végrehajtódni, ha pedig variable1 értéke egyenlő vagy kisebb, mint 0, akkor pedig az else ágban lévő utasítások hajtódnak végre.
variable1 értéke nagyobb vagy egyenlő mint variable2 értéke:
variable1 >= variable2kisebb vagy egyenlő:
variable1 <= variable2egyenlő-e, egyenlőségvizsgálat (ne keverjük össze az = operátorral):
variable1 == variable2nem egyenlő-e:
variable1 != variable2- olyak logikai kifejezéseket amelyekben &&, valamint || operátorok szerepelnek
Ezekre a 2. és a 6. példában nézünk megoldást.
- logikai változók neveit
Logikai kifejezések, függvényhívások eredményeit eltárolhatjuk logikai változókban.
Ennél a példánál, ha a bool_variable nevű változó értéke igaz, vagyis true, akkor az if ágban lévő utasítások fognak végrehajtódni. Ha a bool_variable nevű változó értéke hamis, azaz false, akkor pedig az else ágban lévő utasítások fognak végrehajtódni.
if (bool_variable) {
//statements
} else {
//statements
}A ! operátorral tudjuk negálni, tagadni egy logikai kifejezés, logikai változó értékét. Ekkor ha a bool_variable értéke false, akkor fognak az if ágban lévő utasítások végrehajtódni, ha pedig true, akkor az else ágban lévőek.
if (!bool_variable) {
//statements
} else {
//statements
}Logikai változókat például a programozási tételekben fogunk használni.
- nem logikai kifejezések
ha nem logikai kifejezést adunk meg az ifnek paraméterül, akkor a kifejezés eredménye át fog konvertálódni logikai értékké (pár bekezdéssel lentebb láthatjuk, hogy hogyan)
if (--i) {
//statements if --i != 0
} else {
//statements if --i == 0
}Ennek talán ciklusoknál több értelme van.
Gyakori hiba:
if (variable = 0) {
//statements
}Ehelyett a programozó jó eséllyel ezt akarta írni:
if (variable == 0) {
//statements
}Pedig a felső is lefordul, le is fut, csak teljesen más működést eredményez.
- nem logikai változók
ha nem logikai változót adunk meg az ifnek paraméterül, hanem más típusú változót, akkor annak a változónak az értéke át fog konvertálódni logikai értékké (pár bekezdéssel lejjebb láthatjuk hogyan)
- függvényhívások
ha a függvény visszatérési értéke igaz, vagy azzal egyenértékű, akkor az if blokkjában lévő utasítások lesznek végrehajtva, ha a függvény visszatérési értéke hamis, vagy azzal egyenértékű, akkor pedig az else blokkjában lévő utasítások lesznek végrehajtva
if (function_example()) {
//statements if the function's return value is true or equivalent with true
} else {
//statements if the function's return value is false or equivalent with false
}- mellékhatással rendelkező utasítások
például ha itt a felhasználó nem számot ad meg, hanem például szöveget, akkor az else ágban lévő utasítások hajtódnak végre. (bár ezt a konkrét példát (input validation) talán inkább ciklussal szoktuk megoldani):
int variable_example;
if (std::cin >> variable_example) {
std::cout << "the value of variable_example: " << variable_example << '\n';
} else {
std::cout << "error in input\n";
std::cin.clear();
}Ez utóbbi példa szokatlannak tűnhet, mivel vannak olyan programozási nyelvek (pl. Pascal), amikben ilyesmivel nem találkozhatunk. Egyes coding standardok szerint kerülendő, de biztosan találkozunk vele mások kódjában.
Ennek is inkább a ciklusoknál van értelme:
Logikai konverziók, avagy hogyan kell érteni azt, hogy igaz vagy azzal egyenértékű
Igaz és a vele egyenértékű értékek, kifejezések
Létezik true (igaz), mint logikai literál. Például kezdőértékül adhatjuk egy logikai változónak.
bool b = true;Ha más típusokról történik konverzió logikai (boolean) típusra, akkor a következő értékek (vagy olyan kifejezések, amiknek ezek egyike az eredménye) igazzá konvertálódnak:
bool b = 1;bool b = -1;bool b = '0';bool b = 'a';bool b = "";bool b = "\0";Ezt úgy is szokták nevezni, hogy egy kifejezés/érték truthy, vagyis logikai kontextusban true-ra értékelődik ki.
Tehát olyan kifejezések konvertálódnak igazzá, amik nem 0-val egyenértékűek. Furcsának tűnhet, hogy például az üres string és a '0' érték nem 0-val egyenértékű. Más programozási nyelvekben ez eltérő lehet.
Hamis és a vele egyenértékű értékek, kifejezések
A hamisnak is létezik literálja, a false. Például kezdőértékül adhatjuk egy logikai változónak.
bool b = false;Ha más típusokról történik konverzió logikai (boolean) típusra, akkor a következő értékek (vagy olyan kifejezések, amiknek ezek egyike az eredménye) hamissá konvertálódnak:
bool b = 0;bool b = 0.0; //or 0. or .0bool b = '\0';bool b = "hello world\0"[11];bool b = "\0"[0];bool b = NULL;bool b = nullptr;Ezt úgy is szokták nevezni, hogy egy kifejezés/érték falsy, vagyis logikai kontextusban false-ra értékelődik ki.
Tehát a nulla és a nullával egyenértékű értékek konvertálódnak hamissá. Más programozási nyelvekben nem biztos, hogy ugyanezek a nullával egyenértékű értékek.
Ez a két kifejezés kicsit becsapós lehet. Más programozási nyelvekben ez jelenthetne üres objektum literált, esetleg üres tömb literált, de a C++ nyelvben ez az inicializálás (kezdőértékadás egyik módja), vagyis a bool b = '\0'; vagy bool b{}; utasítással egyenértékű. Például ha ezt írjuk, akkor a hibaüzenetből kiderül: bool b = {'\0', '1'};
bool b = {};bool b = {'\0'};Tesztprogram
Ebben a programban két kifejezést nézünk meg, az üres stringet és a stringlezáró karaktert. Az előbbi truthy, az utóbbi falsy.
//thruthy, falsy examples
#include <iostream>
int main() {
//example1
if ("") {
std::cout << "\"\" is truthy\n";
} else {
std::cout << "\"\" is falsy\n";
}
//example2
if ('\0') {
std::cout << "'\\0' is truthy\n";
} else {
std::cout << "'\\0' is falsy\n";
}
}Ebbe a programba az if paramétereként a fent felsorolt értékek közül beilleszthetünk egyet-egyet, és kipróbálhatjuk, hogy azok tényleg igazzal vagy hamissal egyenértékűek-e.
Pl. a "copy/paste your expression here" helyett írjunk 0.0-t.
//thruthy, falsy test
#include <iostream>
int main() {
if ("copy/paste your expression here") { //without ""
std::cout << "your expression is truthy\n";
} else {
std::cout << "your expression is falsy\n";
}
}Explicit logikai konverziók
A fentebbi példák implicit logikai konverziók voltak. Az explicit logikai konverziók így néznek ki:
static_cast<bool>("");!!('\0');Például ha nem akarjuk változó értékéül adni az átkonvertált kifejezést, hanem rögtön ki akarjuk íratni:
std::cout << static_cast<bool>("") << '\n';std::cout << !!('\0') << '\n';Hasonló más programozási nyelvekben:
- developer.mozilla.org - truthy
- developer.mozilla.org - falsy
- php.net - type comparison tables
- freecodecamp.org - Truthy and Falsy Values in Python
Nem szoktuk kiírni, ha azt vizsgáljuk, hogy egy logikai változó értéke igaz vagy hamis
Például ehelyett:
if (b_variable == true) {/*statements*/}Ezt szoktuk írni:
if (b_variable) {/*statements*/}Illetve ehelyett:
if (b_variable == false) {/*statements*/}Ezt szoktuk írni:
if (!b_variable) {/*statements*/}1. példa: egy szám abszolút értéke
Az első példában egy, a felhasználó által megadott szám abszolút értékét íratjuk ki. Az abszolút érték ugyebár egy szám 0-tól mért távolsága, mely minden esetben egy pozitív érték.
Ha a megadott szám negatív (vagyis kisebb, mint 0), akkor a -1-el megszorzott értékét íratjuk ki (így csinálunk belőle pozitívat, hogya megszorozzuk -1-el), ha pedig a szám 0, vagy 0-nál nagyobb, akkor egyszerűen csak kiíratjuk, módosítás nélkül.
//absolute value
#include <iostream>
int main () {
double number_input{};
std::cout << "Please enter a number (with not too many digits)" << '\n';
std::cin >> number_input;
std::cout << "The absolute value of the input number: ";
if (number_input < 0) {
std::cout << -number_input << '\n';
} else {
std::cout << number_input << '\n';
}
}Általában egy programnak sokféle megoldása van. Még egy ilyen egyszerű példaprogram esetén is vannak más megoldások.
Például a number_input változó módosított értékét el is tárolhattuk volna kiíratás előtt. Ez esetben nincs szükség else ágra, hiszen csak akkor kell módosítani a számot, ha az negatív.
if (number_input < 0) {
number_input = -number_input;
}
std::cout << number_input << '\n';if (number_input < 0) {
number_input *= -1;
}
std::cout << number_input << '\n';A feltételt is megfogalmazhattuk volna másképp. A number_input < 0 logikai kifejezés ellentettjét (number_input >= 0) is megadhattuk volna feltételnek. Ezt bármilyen logikai kifejezés esetén megtehetjük, de ügyeljünk arra, hogy helyesen adjuk meg az adott logikai kifejezés ellentettjét, és hogy ekkor az elágazás egyes ágai felcserélődnek.
if (number_input >= 0) {
std::cout << number_input << '\n';
} else {
std::cout << -number_input << '\n';
}Egyébként ha includeoljuk a C++ standard library cmath nevű header fájlját, akkor használhatjuk az abs nevű függvényt. Emlékeztetőül: itt most ne a matematikai függvényekre és a koordináta rendszerre gondoljunk, az abs nevű függvény csupán megadja egy double vagy int típusú érték abszolút értékét:
//absolute value
#include <iostream>
#include <cmath> //abs()
int main () {
double number_input;
std::cout << "Please enter a number (with not too many digits)" << '\n';
std::cin >> number_input;
std::cout << "The absolute value of the input number: " << abs(number_input) << '\n';
}2. példa: egy szám paritása
A következő példában a felhasználó által megadott szám paritását (páros vagy páratlan) íratjuk ki. Egy egész szám páros, ha kettővel elosztva 0 maradékot ad, és páratlan, ha 1-et, vagy -1-et (lényegtelen, hogy hányszor van meg benne a 2, csak a maradék a lényeg). (Nem egész szám nem lehet se páros, se páratlan, mivel, ha el is osztanánk őket maradékosan, a maradék se 0, se 1 nem lenne).
Egész számot kérünk be a felhasználótól, de ha mégis valós számot ad meg (pl. -4.33), akkor implicit típuskonverzió történik, és a megadott valós szám egész számmá konvertálódik (mivel egy int típusú változóba kérjük be az értéket a felhasználótól). Ezt akár le is ellenőrízhetjük, ha kiíratjuk a bekért értéket is.
A maradék megállapításához a % operátort használhatjuk. Például a 7 % 3 kifejezés eredménye 1, mivel a 7-ben 2-szer van meg a 3, és 1 a maradék. Másképp fogalmazva 3*2 + 1 = 7.
A % operátor operandusai csak egész szám típusú (int, vagy ahhoz hasonló: pl. short int, long int... stb.) értékek lehetnek. Ha lebegőpontos szám típusú (float, double, long double) értékkel próbáljuk használni, fordítási hibát kapunk.
Két érték egyenlőségének a vizsgálatára az == operátort használhatjuk (nem csak számok esetén). Az így kapott logikai kifejezés igaz lesz, ha az == operátor bal, és jobb oldalán szereplő kifejezések eredménye/értéke megegyezik (akár implicit típuskonverziót követően).
Pl. variable_example == 10 logikai kifejezés jelentése: variable_example nevű változó értéke egyenlő-e 10-el.
Ügyeljünk arra, hogyha két különböző típusú, de egyenértékű dolgot hasonlítunk össze, akkor az összehasonlítás eredménye true (igaz) érték lesz. Pl. 0 == '\0' vagy 0 == 0.0 vagy 0 == nullptr kifejezések értéke true (igaz).
A C++ nyelvben nincs === opetátor, mint Javascriptben, ami implicit típuskonverzió esetén false (hamis) értéket ad vissza.
Pl. a 10 == 10.0 kifejezés értéke igaz, míg Javascriptben a 10 === 10.0 kifejezés értéke hamis.
Az összehasonlító operátor (==) lebegőpontos számok között nem biztos, hogy jól működik, ezért kerülendő olyan kódot írni, ahol két lebegőpontos számot hasonlítunk össze == operátorral.
A példaprogram forráskódja:
#include <iostream>
int main () {
int number_input;
std::cout << "Please enter a number (with not too many digits):" << endl;
std::cin >> number_input;
std::cout << "The input number " << number_input << " is ";
if (number_input % 2 == 0) {
std::cout << "even.\n";
} else {
std::cout << "odd.\n";
}
}Egy logikai kifejezés ellentettjének magadásához nem minden esetben muszáj megfogalmazni azt. Az egyenlőségvizsgálat ellentettjét megadhatjuk a != (nem egyenlő) operátorral is. Tehát például a number_input % 2 == 0 logikai kifejezés elleltéte megadható így is: number_input % 2 != 0.
Van lehetőség továbbá az egész feltétel tagadására is, ha eléírunk egy ! (negáló/tagadó) operátort, de ha azt akarjuk, hogy a negálás legyen érvényes az egész feltételre, akkor ne felejtsük el zárójelezni az egész logikai kifejezést. Például:
if ( !(b % 2 == 0) ) {
cout << "paratlan" << endl;
} else {
cout << "paros" << endl;
}Ha esetleg a number_input % 2 == 0 logikai kifejezés ellentétét szeretnénk hosszabban megfogalmazni (röviden number_input % 2 != 0), ne felejtsük el, hogy az nem a number_input % 2 == 1, hiszen a negatív páratlan számok 2-vel osztva -1-et adnak maradékul. Ekkor tehát azt kell vizsgálnunk, hogy a number_input % 2 == 1, illetve a b % 2 == -1 logikai kifejezések közül igaz lesz-e az egyik. Ezt az || (or) operátorral tehetjük meg. Tehát a number_input % 2 == 0 logikai kifejezés ellentettje: number_input % 2 == 1 || number_input % 2 == -1
Az || operátor true (igaz) értéket ad eredményül, ha a bal és jobb oldalán álló logikai kifejezések közül legalább az egyik értéke true, bár itt most nem fordulhat elő olyan eset, hogy mindkét kifejezés értéke igaz legyen.
A || (logikai vagy operátor) eredménye akkor igaz, ha bármelyik részfeltétel igaz, és akkor hamis, ha minden részfeltétel hamis. Kettőnél több részfeltételre is alkalmazható a művelet.
Ha az || operátor bal oldalán lévő logikai kifejezés értéke igaz, akkor a program nem fogja megvizsgálni a másik kifejezés értékét, hiszen (ha legalább az egyik logikai kifejezés értéke igaz, akkor) már tudható, hogy az || operátorral képezett teljes logikai kifejezés is igaz lesz. Ezt mohó (greedy) kiértékelésnek (angolul short circuit) nevezzük.
Vannak olyan programnyelvek is, amik biztonsági okokból akkor is kiértékelnek minden kifejezést akkor is, ha azok nem szükségesek a végeredmény eldöntéséhez (pl. ADA).
Másképp fogalmazva:
true || x == true
false || x == x
Létezik | (bitenkénti vagy) operátor is, ami nem mohó kiértékeléssel dolgozik. A || és | operátor közötti különbség, hogy if (fv1() || fv2()){} esetén az fv2() nem fut le, ha fv1() hamisat ad vissza, az if (fv1() | fv2()){} esetén viszont az fv2() mindenképp végrehajtásra kerül.
Mindenesetre bármilyen módon is fogalmazunk meg feltételeket, logikai kifejezéseket, fordítsunk rá különös figyelmet, gondoljuk át, hogy egy elágazás egyes ágainak milyen eseteket kell lefednie, mert ebben könnyű hibázni.
3. példa: páros random szám
Páros random számot könnyen generálhatunk elágazások segítségével. Ha páratlant generált, hozzáadunk egyet. Kivéve, ha az intervallum maximális értékével egyenlő a random generált szám (páratlan esetén), akkor kivonunk belőle egyet.
//random even integral number between 1 and 10
//including 10
#include <iostream>
#include <random>
int main() {
const int min = 1;
const int max = 10;
std::random_device rnd_device;
std::mt19937 rnd_generator(rnd_device());
std::uniform_int_distribution<int> int_dist(min,max);
int random_number = int_dist(rnd_generator);
if (random_number % 2 != 0) {
if (random_number == max) {
--random_number;
} else {
++random_number;
}
}
std::cout << random_number << '\n';
}4. példa: melyik szám nagyobb
Egy elágazásnak természetesen nem csak két ága lehet, hanem több is. Például ha a második, harmadik... sokadik ág nem else, hanem else if. Ekkor természetesen több feltételt is meg kell adni, csak az utolsó ágban nem kell feltételt megadni (az utolsó ág feltétele nyilván az eddigi ágak ellentéte lenne).
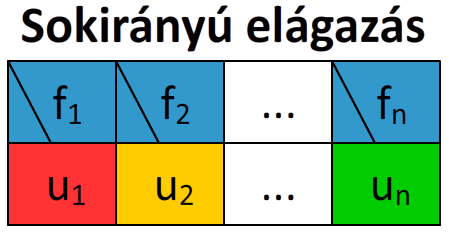
A sokirányú elágazás struktogramja. Az f a feltétel rövidítése, az u pedig az utasításé.
Ebben a programban bekérünk a felhasználótól két számot, és kiíratjuk, hogy egyenlőek, vagy az egyik szám a nagyobb, vagy a másik szám a nagyobb.
//maximum of 2 numbers example
#include <iostream>
int main() {
std::cout << "Please enter 2 numbers\n";
std::cout << "This program decides which is the larger\n";
double number1{}, number2{};
std::cin >> number1 >> number2;
if (number1 == number2) {
std::cout << "The two input numbers are equal\n";
} else if (number1 > number2) {
std::cout << number1 << " is larger than " << number2 << '\n';
} else /*if (number1 < number2)*/ {
std::cout << number2 << " is larger than " << number1 << '\n';
}Ügyeljünk arra, hogy olyan feltételeket adjunk meg az egyes ágakban, amiknek nincs közös metszete, különben a programunk jó eséllyel nem úgy fog működni ahogy elvárnánk.
Mi a különbség a sokirányú elágazás (if-elseif-else...) és különálló, else blokk nélküli ifek között?
Különálló ifek esetén mindenképp ügyelni kell arra, hogy a feltételeknek ne legyen közös metszete (a feltételek diszjunktak legyenek), kivéve persze ha valamilyen oknál fogva ez az elvárás. Továbbá különálló ifek esetén mindenképp megtörténik a feltételek ellenőrzése (ami ront a program teljesítményén), míg egymásba ágyazott if-else-k esetén ha az egyik feltétel teljesül, akkor a további blokkok figyelmen kívül lesznek hagyva, a feltételeik nem kerülnek ellenőrzésre.
5. példa: centiméter/inch konvertálás
Ez a példa abban tér el az előzőtől, hogy amíg az előzőben az else ág valójában egyetlen fennmaradó lehetőséget fed le, ebben a példában az else ágban sok esetet kezelünk. Erre is gondoljunk, amikor sokágú elágazások kódját fogalmazzuk meg.
//cm/inch conversion
#include <iostream>
int main() {
const double cm_per_inch = 2.54;
std::cout << "This program converts a centimeter value to an inch value or an inch value to a centimeter value\n";
std::cout << "Please enter a number, and the unit type of the input value\n";
double input_number{};
std::string unit{};
std::cin >> input_number >> unit;
if (unit == "i" || unit == "inch") {
std::cout << input_number << " inch == " << cm_per_inch * input_number << " cm\n";
} else if (unit == "cm" || unit == "centimeter") {
std::cout << input_number << " cm == " << input_number / cm_per_inch << " inch\n";
} else {
std::cout << "Sorry, I don't know a unit called ' " << unit << " ' \n";
}
}példa forrása: Programming principles and practice using C++ könyv
6. példa: egy karakter betű, szám, írásjel vagy speciális karakter?
Ebben a példában bekérünk a felhasználótól egy karaktert és kiíratjuk, hogy ez a karakter betű, szám, írásjel vagy speciális karakter, valamint kiíratjuk a karakter ASCII kódját is.
Az alaptípusok jellemzői tananyagrészben már esett szó arról, hogy egy char típusú változóban valójában az adott karakter ASCII kódjának megfelelő egész számot tároljuk, és amikor cout-tal kiíratjuk az értékét, akkor az ASCII kódnak megfelelő karakter íródik ki. Az ASCII táblában megtekinthetjük, hogy milyen ASCII kódhoz milyen karakter tartozik:
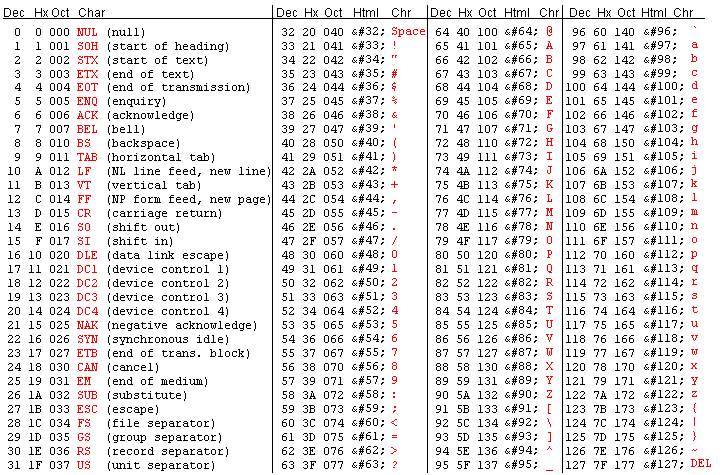
Például úgy tudjuk leellenőrízni, hogy egy karakternek tényleg a táblázatban lévő szám az ASCII kódja, ha explicit típuskonverzióval kiíratjuk.
char char_example = 'b';
std::cout << static_cast<int>(char_example) << '\n';
A példaprogramban azt fogjuk vizsgálni, hogy a felhasználó által megadott karakterérték ASCII kódja milyen tartományba esik. Ha megnézzük az ASCII táblát, akkor láthatjuk, hogy például a betűk 65 és 90, valamint 97 és 122 között találhatók, a számok pedig 48 és 57 között.
Mivel a char típusú értékek valójában számok, ezért ugyanolyan műveleteket végezhetünk velük, mint az int típusú értékekkel. Például ehelyett a kifejezés helyett:
48 <= char_input <= 57akár ezt is írhatjuk:
'0' <= char_input <= '9'A karakter literálokat talán könnyebb megjegyezni, mint az egyes karakterek ASCII kódját.
Fontos: amikor azt vizsgáljuk, hogy egy valamilyen szám típusú változó (a char típus itt tekinthető egész számnak) értéke két érték közé esik-e, akkor a logikai kifejezést a programkódban NEM így kell megfogalmazni: '0' <= char_input <= '9'., hanem így: '0' <= char_input && char_input <= '9'
(A '0' <= char_input <= '9' kifejezés esetén ugyanis az történne, hogy a program először kiértékelné a 47 < char_input részkifejezést, ennek az eredménye true (igaz), vagy false (hamis) lenne, a következő részkifejezésnél pedig az adott logikai érték számmá konvertálódna (a true 1-é, a false pedig 0-vá), és ezen számértékek egyikét hasonlítaná össze a program az 58-al, ami helytelen működést okozna).
Ebben a kifejezésben ('0' <= char_input <= '9') valójában két dolgot vizsgálunk, mely két dolognak egyaránt igaznak kell lennie ahhoz, hogy a kifejezés végeredménye igaz legyen. Erre az esetre az && (and) operátort használhatjuk. A helyes logikai kifejezés így néz ki: '0' <= char_input && char_input <= '9'
A && (logikai és operátor) eredménye igaz, ha minden részfeltétel igaz, hamis, ha bármelyik részfeltétel hamis.
Hasonlóan mint az || (or) operátornál, az && operátor esetén a program csak az első részkifejezést értékeli ki ha annak az eredménye hamis, hiszen abból már tudható, hogy a végeredmény is hamis lesz, mivel ahhoz, hogy a végeredmény igaz legyen, minden egyes && operátorral összekapcsolt részkifejezésnek igaznak kell lennie.
false && x == false
true && x == x
Arra is lesz példa, hogy két darab && operátoros logikai kifejezést kell összekapcsolni egy || operátorral. Ez konkrétan a betűk esetén fog előfordulni, hiszen a betűk két különböző tartományban is lehetnek (65-től 90-ig a nagybetűk, 97-től 122-ig pedig a kisbetűk).
Az egyik tartomány:
'A' <= char_input && char_input <= 'Z'A másik tartomány:
'a' <= char_input && char_input <= 'z'A két tartomány összekapcsolva:
( ( 'A' <= char_input && char_input <= 'Z' ) || ( 'a' <= char_input && char_input <= 'z' ) )Bár jelen példa esetén nem okoz hibát ha nem zárójelezzük külön-külön az && operátoros kifejezéseket, de azért legyen megemlítve, hogy logikai kifejezések esetén különösen figyeljünk a zárójelezésre.
Az egyszerűség kedvéért az írásjelek és a speciális karakterek között a program nem tesz különbséget, mivel az írásjelek viszonylag szétszórtan helyezkednek el az ASCII táblában, így a hozzá tartozó feltétel is bonyolult lenne. Persze ha valaki szeretné, gyakorlásképp megcsinálhatja :)
A példaprogram forráskódja:
#include <iostream>
int main () {
char char_input;
std::cout << "Kerem adjon meg egy tetszoleges karaktert:\n";
std::cin >> char_input;
std::cout << "A megadott karakter (" << char_input << ") ASCII kodja: "
<< static_cast<int>(char_input) << ", tipusa: ";
if ( '0' <= char_input && char_input <= '9') {
std::cout << "szam.\n";
} else if ( ( 'a' <= char_input && char_input <= 'z' )
|| ( 'A' <= char_input && char_input <= 'Z' ) ) {
std::cout << "betu.\n";
} else {
std::cout << "irasjel vagy specialis karakter.\n";
}
}7. példa: kisbetű esetén nagybetűsítés és fordítva
Az előző példa alapján könnyen írhatunk egy olyan programot, ami kiírja a felhasználó által megadott karaktert, de betűk esetén kisbetűsít, illetve nagybetűsít, attól függően, hogy kis- vagy nagybetűt adott meg a felhasználó.
Kisbetűsítést és nagybetűsítést kétféleképpen is meg lehet oldani. Egyrészt az ASCII táblákban észrevehetjük, hogy a nagybetűknek 32-vel kisebb az ASCII kódja, mint a kisbetűknek, ezért ha a nagybetűkből kivonunk 32-t, megkapjuk a megfelelő kisbetűt, vagy ha egy kisbetűhöz hozzáadunk 32-t, megkapjuk a megfelelő nagybetűt.
A másik megoldás kisbetű esetén (ha kivonjuk belőle a kis a betűt, akkor 0-tól annyival lesz távolabb, amennyivel távolabb volt a kivonás előtt a kis a betűtől, majd ha hozzáadunk egy nagy A betűt, akkor a nagy A betűtől lesz annyivel távolabb, mint amennyivel a kivonás előtt távolabb volt a kis a betűtől):
char_input = char_input - 'a' + 'A';Illetve nagybetű esetén:
char_input = char_input - 'A' + 'a';A példakódban az első megoldást alkalmazzuk.
Tegyük fel, hogy ennél a bekérésnél a felhasználó egy kisbetűt (pl. b) ad értékül:
std::cin >> char_input;Ha a cout << char_input - 32; utasítást használjuk, akkor a program nem a nagybetűsített karaktert fogja kiírtni, hanem annak az ASCII kódját. Ha magát a karaktert szeretnénk kiíratni, akkor használjuk a static_cast<char>( char_input - 32) kifejezést, vagy pedig külön utasításban végezzük el a char_input - 32 műveletet, majd a coutnak a char típusú változó nevét (jelen esetben karakter) adjuk csak paraméterül.
#include <iostream>
int main () {
char char_input{};
std::cout << "Kerem adjon meg egy tetszoleges karaktert:\n";
std::cin >> char_input;
std::cout << "A beolvasott ertek";
if ('A' <= char_input && char_input <= 'Z') {
std::cout << " kisbetusitve: " << static_cast<char>(char_input += 32);
} else if ('a' <= char_input && char_input <= 'z') {
std::cout << " nagybetusitve: " << static_cast<char>(char_input -= 32);
} else {
std::cout << ": " << char_input ;
}
}8. példa: függvények
Gyakran előfordul, hogy az egyes ágakba nem utasításokat írunk, hanem függvényhívásokat. Ez valójában a kód szervezettségét javítja, hiszen a függvényekben szintén utasítások szerepelnek (amiket akár az egyes ágakba is beleírhatnánk közvetlenül).
if (traffic_light == "green") {
go();
} else if (traffic_light == "red") {
wait();
}Változók láthatósága
Hatókör (scope)
Ha egy változót egy elágazás valamely blokkján belül definiálunk, akkor azt a változót nem érhetjük el az elágazás adott blokkján kívül (a másik blokkjában sem).
Tehát ügyeljünk arra, hogyha egy változót nem csak az elágazás egyik blokkjában szeretnénk használni, hanem azon kívül is, akkor a definícióját az elágazás blokkjain kívül helyezzük el.
//error
if ( /*condition*/ ) {
int variable_example;
//statements
} else {
std::cout << variable_example;
}//error
if ( /*condition*/ ) {
std::string variable_example;
//statements
} else {
//statements
}
cout << variable_example;Elfedés (variable shadowing)
Amennyiben az elágazás egyik blokkján belül definiálunk egy a blokkon kívül már definiált változóval azonos nevű változót, akkor az elágazás azon ágán belül a kívül definiált változót nem érhetjük el.
int a = -1; //you can not reach this variable...
if ( /*condition*/ ) {
int a = 3;
//...from here
std::cout << a << '\n'; //3
} else {
std::cout << a << '\n'; //-1
}
std::cout << a << '\n'; //-1Kivételt képeznek a globális változók (melyeket a függvények blokkján kívül (beleértve a main függvényt is) definiálunk). Elfedés esetén a :: operátorral elérhetjük a globális változókat.
//global variable example
char c = 'y';
int main () {
//local variable example
char c = 'n';
std::cout << c << '\n'; //ekkor n lesz kiírva
std::cout << ::c << '\n'; //ekkor y lesz kiírva
}Elrejtés
Ha azt szeretnénk, hogy egy változót csak az elágazás két ágában lehessen használni, de az elágazáson kívül ne, akkor létrehozhatunk egy önálló, az elágazástól független blokkot.
Ez például azért hasznos, mert így biztosan elkerülhetjük, hogy egy változó a kód további részeiben definiált változókkal névütközést okozzon, illetve azt is elkerülhetjük, hogy esetleg véletlenül hivatkozzunk rá a kód további részeiben (hiszen egy hosszú, szövevényes kódban nem könnyű eligazodni).
{
int a;
//itt használhatjuk az a változót
if ( /*feltétel*/ ) {
//itt is használhatjuk az a változót
} else {
//itt is használhatjuk az a változót
}
//itt is használhatjuk az a változót
}
//ezen a ponton megszűnik az a változó érvényességeEhelyett C++17 vagy újabb szabvány szerint értelmezett kódban használhatunk úgynevezett init statementeket az elágazásokban.
Fontos: a hatókörről és elfedésről leírtak nem csak az elágazások blokkjaira vonatkoznak, hanem ciklusok blokkjaira is, illetve a függvények blokkjaiban definiált változók is csak az adott függvényben érhetőek el, a függvényen kívül nem.
Hibalehetőség
== és = operátorok összekeverése
Az == (egyenlőségvizsgálat) operátort ne keverjük az = (értékadás) operátorral, mert akkor a program hibásan fog működni, vagy fordítási hibát kapunk.
Előfordulhat, hogy ehelyett:
if (variable_example == 10) {/*statements*/}Véletlenül ezt írjuk:
if (variable_example = 10) {/*statements*/}Ez utóbbi nem okoz fordítási hibát, csak bizonyos esetben, például ha a variable_example nevű változó const típusminősítővel lett létrehozva.
Ha nem okoz fordítási hibát, akkor az történik, hogy a variable_example értéke átállítódik 10-re, és az igaz ág blokkjában lévő utasítások kerülnek végrehajtásra (akkor is, ha a variable_example értéke ezt megelőzően nem 10 volt, pedig elvileg azt akarnánk vizsgálni, hogy 10-e az értéke, és az igaz ág blokkjában lévő utasításokat csak akkor szeretnénk végrehajtani, ha a variable_example értéke 10).
Yoda conditional
Ha szerepel literál az egyenlőségvizsgálatot tartalmazó kifejezésben, akkor érdemes megfogadni azt a tanácsot, hogy a literált írjuk az egyenlőségvizsgálat bal oldalára, így ha véletlenül egy egyenlőségjelet is írnánk a kettő helyett, mindenképp fordítási hibát kapunk, hiszen a literáloknak nem lehet értéket adni.
if (10 == variable_example) {/*statements*/}Csellengő else
Ha csak egy utasítást akarunk írni az if vagy az else blokkjába, akkor nem kötelező kitenni a kapcsos zárójeleket. Például:
if( /*condition*/ )
//statement
else
//statementHa viszont több elágazást ágyazunk egymásba, akkor nem biztos, hogy tudni fogjuk, hogy az else ág melyik ifhez tartozik. Ilyenkor a csellengő else a legbelsőbb ifhez tartozik. Ebben a példában könnyen kiderülne, ha az else a külső ifhez tartozna. (Az indentálás C++ nyelvben nem befolyásolja a blokkokat, csak a kód olvashatóságát segíti).
//dandling else
#include <iostream>
int main() {
if (2 == 3)
std::cout << "2 == 3\n";
if (4 == 4)
std::cout << "4 == 4n";
else
std::cout << "4 != 4\n";
}Szintén hibalehetőség, hogy megfeledkezhetünk arról, hogy így csak egyetlen utasítás tartozik az if vagy else ághoz, ami ugyan nem biztos, hogy fordítási hibát okoz, de a program biztosan nem fog jól működni.
//error
if (/*condition*/)
//statement1
//statement2 is not in the block of ifÉrdemes minden esetben kiírni a blokkokat jelző kapcsos zárójeleket.
true és false értékek kiíratása cout-tal
Alapbeállítás szerint a cout true helyett 1-et, false helyett 0-t ír ki. Ezzel az utasítással lehet átállítani, hogy konkrétan true és false szöveget írjon ki a cout:
std::cout.setf(std::ios::boolalpha);Ezzel pedig visszaállítani, hogy true helyett 1-et, false helyett 0-t írjon ki:
std::cout.unsetf(std::ios::boolalpha);Erre már láthattunk példát az eddigi tananyagrészekben is:
A bool típus méretéről
A logikai (bool) típusú változók (az átlagos felhasználói számítógépeken) 1 bájt foglalódik le a számítógép memóriájában. Igaz, hogy effektíve csak kétféle értéket tárolunk bennük (melyhez elég lenne 1 bit is), de 1 bájt a legkisebb címezhető egység a számítógép memóriájában.
Ha kiíratjuk a (bool típussal paraméterezett) numeric_limits sablonosztály digits adattagjának értékét, akkor azt az értéket kapjuk, ami az adott típus effektív értékének tárolásához szükséges (bitben megadva).
A sizeof operátorral viszont az adott típus számára lefoglalt tényleges méretet kapjuk meg.
// #include <limits>
std::cout << std::numeric_limits<bool>::digits << " bit" << '\n'; //1 bit
std::cout << sizeof(bool) << " byte" << '\n'; //1 byteEgy osztályon belül bitmezők segítségével megoldható, hogy 8 darab bool típusú érték tárolásához csak 1 bájtnyi memóriát használjunk, de erről ebben a tananyagban nem lesz szó.
Érdekességképpen elmondható, hogy noha az int test = true; utasítás esetén a test nevű változó értéke 1 lesz, int test = false; esetén pedig 0, ugyanakkor ha definiálunk egy (lokális) logikai változót, nem adunk neki kezdőértéket és később értéket (tehát a számára lefoglalt memóriaterületen lévő memóriaszemét lesz az értéke), majd ezt követően kiíratjuk az értékét cout-tal, akkor a kiírt érték nem csak 0 vagy 1 lehet, hanem egy 0 és 255 közötti szám.
A következő fejezet tananyagát felhasználva ebben a kis kódrészletben létrehozunk egy 100 elemű, bool típusú tömböt (ami olyan, mintha 100 bool típusú változót hoznánk létre, csak nem kell őket egyessével elnevezni) és (szóközökkel elválasztva) kiíratjuk az értéküket cout-tal, anélkül, hogy kezdőértéket, vagy értéket adtunk volna nekik. Tekintsük meg az eredményt.
Természetesen ebben az esetben is csak a 0 érték jelenti a logikai hamis értéket. Továbbá ismételten megemlítem, amit már az előző részben is megemlítettem, hogy mindig gondoskodjunk arról, hogy a programkódunkban szereplő változók kapjanak kezdőértéket, attól függetlenül, hogy ebben a példaprogramban éppen azt mutatom meg, hogy mi történik, ha nem.
//initial (garbage) value of bool without initialization
#include <iostream>
int main() {
bool test_array[100];
for (const bool& test_elem : test_array) {
std::cout << test_elem << ' ';
}
}Egyéb tananyagok
- fluentcpp.com - How to Make If Statements More Understandable
- fluentcpp.com - Do Understandable If Statements Run Slower?
Előző tananyagrész: alapvető típuskonverziók
Következő tananyagrész: switch-case, ternáris operátor
