
Az előző tananyagrészből megtanulhattuk hogyan készíthetünk egy forrásfájlból futtatható programot.
Ebben a tananyagrészben már a forrásfájlok tartalmáról lesz szó, de csak nagyon egyszerű utasításokról amik a parancssorba írnak ki valamilyen szöveget vagy karaktert.
Előző tananyagrész: első lépések
Következő tananyagrész: megjegyzések (kommentek) a forráskódban
Tartalom
- main függvény
- C++ standard library
- alapvető kód
- szöveg parancssorba kiíratását elvégző utasítás
- sortörés a parancssorba kiírt szövegben
- példaprogram
- forráskód tagolása, alapvető szintaktikai szabályok
- return 0; utasítás
- return EXIT_SUCCESS; utasítás
- exit(0); utasítás
- std névtér, using namespace std; utasítás
Tekintsük meg annak a programnak a C++ kódját, ami kiírja a parancssorba, azt a szöveget, hogy Hello World. A legtöbb programozás tananyagban ez szokott lenni a legelső példaprogram:
#include <iostream>
int main() {
std::cout << "Hello World!\n";
return 0;
}Az előző tananyagrészben több példát néztünk arra, hogy lehet ebből a kódból futtatható programot készíteni, például:
Ha ebből a kódból futtatható programot készítünk, és azt a programot futtatjuk, akkor valami ilyesmit láthatunk:
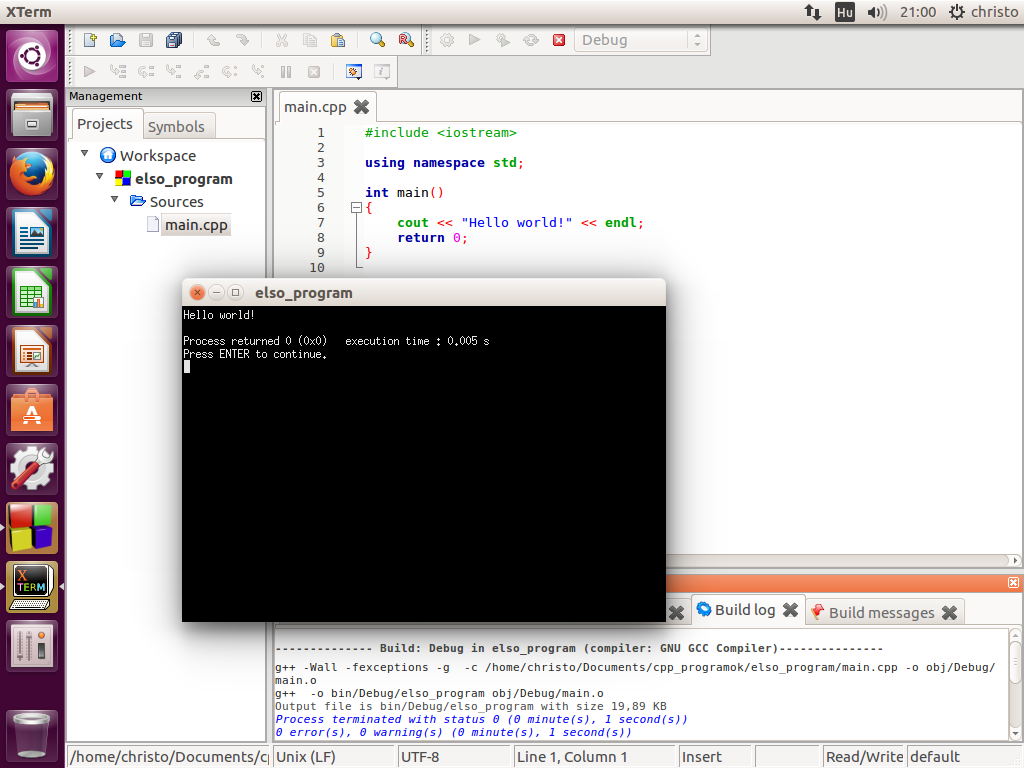
Jellemzően Windowsban előfordulhat, hogy ez a parancssoros ablak ahogy megnyílik, rögtön be is záródik. Erre a problémára az alábbi tananyagrészben láthatunk megoldásokat:
Ezt persze a jelenlegi tananyagrész elolvasása után érdemes megtekinteni.
Érdekességképp tekintsük meg a Hello World szöveget (parancssorba) kiíró program kódját Phyton programozási nyelven:
print("Hello World!")Ez sokkal egyszerűbb mint a C++ program kódja. Na de akkor miért érdemes mégis C++-t tanulni? Egyrészt azért mert gyorsabb programokat lehet vele készíteni, mint Phytonnal, másrészt azért, mert ha C++-t tanulunk, könnyen megérthetjük például a C#, Java és sok más programozási nyelven írt kódokat is.
Annyit a C++ példaprogam kódjáról is könnyű eldönteni, hogy melyik utasítás (jelen esetben melyik sor) az, ami a Hello World szöveg kiíratását végzi el:
std::cout << "Hello World!\n";
Viszont ha csak ennyit írnánk a példaprogram forrásfájljába, abból nem tudnánk futtatható programot készíteni. Egy C++ nyelven írt program esetén szükség van a többi utasításra is.
Ebben a tananyagrészben:
- megnézzük, hogy nagyjából mit jelentenek ennek a példaprogramnak az egyes utasításai
- megnézzük, hogy milyen egyéb utasítások, kifejezések szoktak szerepelni a Hello World példaprogramokban
Alapvető tudnivalók
Szabványos és nem szabványos C++ kód
Szabványos C++ kód az, amit minden C++ fordító elfogad. Ami nem szabványos kód, az lehet, hogy az egyik fordítóval jól működik, egy másik fordítót használva viszont fordítási hibát okoz.
A tananyagban törekszünk a C++ szabványt betartani, ugyanakkor szó lesz nem szabványos kódrészletekről, azért, mert mások által írt kódban találkozhatunk velük. Persze a nem szabványos kódrészletek esetén mindig fel lesz tüntetve, hogy ez itt egy nem szabványos kódrészlet.
Függvények
A függvényekre részfeladatokként tekintsünk a programunk forráskódjában. Egy függvény jellemzően olyan részfeladat, művelet, ami bizonyos adatból, adatokból valamilyen egyéb adatot állít elő (ez akár összetett adat (amit pl. rekordnak szoktak nevezni) is lehet).
A C++ nyelvben egy függvény nem feltétlenül ad vissza valamilyen adatot/eredményt, előfordulhat, hogy csak megváltoztatja valaminek az állapotát (pl. kiír a parancssorba vagy valamilyen fájlba egy szöveget, bizonyos elemeket sorbarendez valamilyen szempont szerint).
Egy program forráskódja utasításokból áll. Egy több száz vagy több ezer utasításból álló programnál már nehéz lenne ránézésre eldönteni, hogy melyik utasítás milyen részfeladatot hajt végre a programban. A programozásban többek közt arra lettek kitalálva a függvények (angolul function), hogy az egyes részfeladatokat megvalósító utasítások csoportjait elkülönítsük egymástól. Főként olyan részfeladatokból érdemes egy program forráskódjában függvényt definiálni (készíteni, létrehozni), amiket a programban többször is végre kell hajtani, akár a forráskód különböző pontjain.
Az első néhány példaprogramunk forráskódja csak pár sorból áll, amit nem fogunk részfeladatokra bontani, vagyis nem definiálunk (készítünk, hozunk létre) több függvényt az első példaprogramjaink forráskódjában, a C++ nyelvben két esetben mégis találkozunk függvényekkel még a legegyszerűbb példaprogramok esetén is.
- Ha egy program forráskódjában több függvény szerepel, valahogy el kell tudni dönteni, hogy a program futása melyik függvény végrehajtásával kezdődik. A C++ nyelven írt programok esetén ez a main nevű/azonosítójú függvény. A C++ szabvány szerint a main függvénynek akkor is szerepelnie kell egy C++ nyelven írt program forráskódjában, ha rajta kívül nem definiálunk (nem hozunk létre) más függvényeket.
Ez alól kivételek lehetnek az úgynevezett freestanding programok (pl. boot loaderek, operációs rendszerek), melyek elkészítése haladó programozási ismereteket igényel.
A main függvény tehát egy speciális függvény, nem azt a célt szolgálja, mint általában a függvények, hogy a programunk forráskódját részfeladatokra bontsuk, hanem azt határozza meg, hogy a programunk futtatása hol kezdődik. - Minden C++ fordítóhoz mellékelve van egy úgynevezett C++ standard library, ami alapvető és hasznos dolgokat (többek között függvényeket) tartalmaz, amiket felhasználhatunk a programjaink forráskódjában.
A C++ standard library függvényeire tekintsünk úgy, mint egy utasítással végrehajtható részfeladatokra, amik a háttérben valójában több utasításból állnak, amiket más programozók írtak meg. Angolul ezeket predefined functionnek is szokták nevezni.
Néhány jellemző példa a C++ standard library függvényei által megvalósított részfeladatokra:- egy szöveg karakterei számának megadása
- véletlenszám generálás
- számok, esetleg szavak/szövegek rendezése
Függvények definiálásáról (készítéséről, létrehozásáról) részletes tananyagrész fog szólni.
Szöveg parancssorba kiírását megvalósító program felépítése lépésenként
main függvény
A main függvény egy C++ nyelven írt program belépési pontja, a program lényegi végrehajtása a main függvény első utasításával kezdődik. (Vannak olyan dolgok, amik a main függvény első utasításának végrehajtása előtt megtörténnek, például a globális változók inicializálása, de ez későbbi tananyagrész témája, illetve ami a main függvény első utasításának végrehajtása előtt történik, az többnyire a program lényegi végrehajtása előfeltételének is tekinthető.)
Nem kell a main függvény végrehajtására vonatkozó utasítást írnunk a forráskódba, másképp fogalmazva a main függvényt nem nekünk kell meghívni, a program elindításával a meghívása megtörténik.
A main függvény blokkja: a main függvény blokkjának, törzsének (angolul body) nevezzük a kapcsos zárójelek közötti részt, ahová a main függvényhez tartozó utasításokat írhatjuk.
A main függvény (ha nem írunk bele utasításokat) például így néz ki:
int main() {}Esetleg ilyenekkel is találkozhatunk, ezek is ugyanúgy a main függvény egy lehetséges változatai:
int main(int argc, char* argv[]) {}int main(int argc, char** argv) {}int main(int argc, char* argv[], char* envp[]) {}Modern C++-ban (C++11-es, vagy újabb szabványban) ez is érvényes:
auto main() -> int {}Mások kódjában esetleg ilyenekkel is találkozhatunk, de ezek nem szabványosak:
void main() {}main() {}C nyelvben ilyennel is találkozhatunk:
int main(void) {}C nyelvben ez mást jelent, mint a legelső példa ( int main() {} ), C++ nyelvben viszont egyenértékű a legelső példával, C++ nyelvben ennek a használata kerülendő (bővebb indoklás).
Egyéb nem szabványos, rendszerspecifikus környezetben a main függvény neve eltérő lehet. Ebben a tananyagban ilyenekkel nem foglalkozunk bővebben. Egy Windows specifikus példa:
int wmain(int argc, wchar_t *argv[], wchar_t *envp[]) {}Ha a fent felsorolt első öt példa közül kiválasztjuk valamelyiket, mondjuk a legelsőt (a többiről majd később lesz szó), és beleírjuk, vagy bemásoljuk egy üres forrásfájlba (pl. egy example_001.cpp nevű plain text fájlba), akkor abból a forrásfájlból már futtatható programot tudunk készíteni egy C++ fordító segítségével. Bár a fenti kódrészletekben nem szerepel semmi a main függvény kapcsos zárójelei között, így a belőlük készített futtatható programok nem csinálnak semmi érdemlegeset, az elindításukat követően a futásuk véget is ér.
Fontos, hogy egyszerre csak egy main függvény szerepelhet egy C++ nyelven írt program forráskódjában. Ha egy C++ fordítóval két vagy több main függvényt tartalmazó fájlt vagy fájlokat szeretnénk egyetlen futtatható fájllá alakítani, fordítási hibát kapunk. Persze ha egy szoftverhez több futtatható fájl tartozik (pl. setup.exe és uninstall.exe), akkor mindegyik futtatható fájlhoz tartozó forrásfájlban lehet egy-egy main függvény.
(Trükkösen lehet két main nevű függvény is egy programon belül, például ha az egyiket beletesszük egy osztályba vagy egy névtérbe, de a globális névtérben nem tagfüggvényként csak egyetlen main függvény lehet.
A nem a globális névtérben elhelyezett main függvény valójában nem is main függvény, hanem objektumneve.main függvény, osztalyneve::main függvény vagy nevterneve::main függvény.
Természetesen az osztályok és a névterek későbbi tananyagrész témái.)
Egyéb információk a main függvényről itt érhetők el:
C++ Standard Library
A C++ standard library önmagában csak parancssoros programok készítését teszi lehetővé, de egyes részei használhatók nem parancssoros programok készítéséhez is (pl. a konténereket, algoritmusokat, iterátorokat és adaptorokat tartalmazó STL, mely szintén későbbi tananyag témája).
Bár ennek a tananyagnak a témáját a C++ standard library teljesen lefedi, természetesen érdemes megemlíteni, hogy amit a standard libraryben nem találunk, azt más librarykben kell keresni. Például a boost-ban vagy egyéb librarykben.
A C++ standard library tartalmáról
A standard library több úgynevezett header fájlból (magyarul fejállomány) áll, egy header fájlban jellemzően egy adott témához tartozó dolgok vannak (pl. az iostream fájlban parancssori műveletek, az fstream fájlban fájlműveletek, a cmath fájlban matematikai műveletek, a ctime és a chrono fájlokban idővel/dátummal kapcsolatos műveletek, satöbbi).
A példaprogramokban majd látni fogunk arra vonatkozó példákat, hogy a standard library melyik fájlját mire lehet használni, de természetesen nehéz lenne fejből tudni, hogy melyik fájlban mi található, ezért vannak erről referenciaoldalak is, amiket majd hasznos lehet nézegetni a C++ nyelv tanulása közben: [1], [2], [3], [4], [5]
Szövegek parancssorba való kiíratásához használhatjuk a C++ standard library iostream nevű fájlját. Természetesen ha a standard library egyik fájljában lévő dolgokat használni szeretnénk a programunkbank akkor ezt valahogy jeleznünk kell.
Hogyan használjuk a C++ standard libraryt?
Ha ez az utasítás szerepel a forrásfájlunk elején, akkor a preprocesszor az iostream header fájl (magyarul fejállomány) tartalmát a forrásfájlunkba másolja (értelemszerűen oda, ahol ez az utasítás szerepel), még mielőtt a C++ fordító elkezdené a forrásfájlt futtatható programmá alakítani:
#include <iostream>Mellékes bepillantás a C++ standard library fájljainak tartalmába
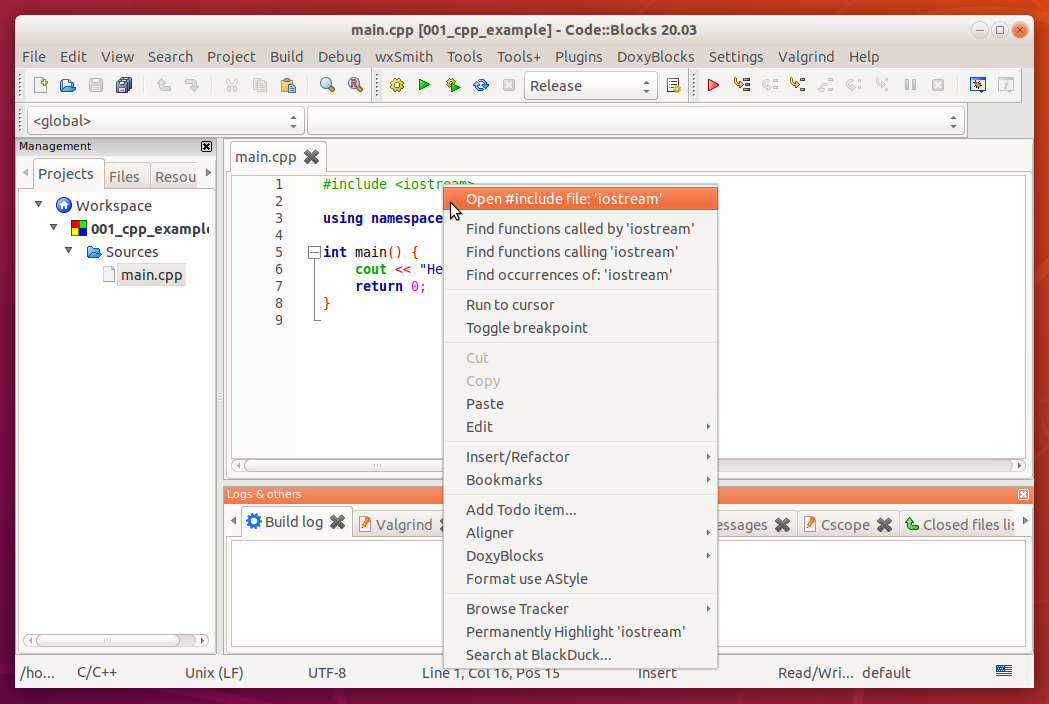
Érdekességképpen megkereshetjük a számítógépünk háttértárolóján a C++ standard library fájljait, például az iostream fájlt, ha például egy integrált fejlesztői környezetben erre az utasításra az egér jobb gombjával kattintunk, majd kiválasztjuk az open file vagy go to document menüpontot.
Például CodeBlocksban:
Egy részlet az iostream fájl tartalmából CodeBlocksban, Linuxon (Ubuntu disztribúció), g++ fordítóval (amit a build-essential csomag részeként telepítettünk):
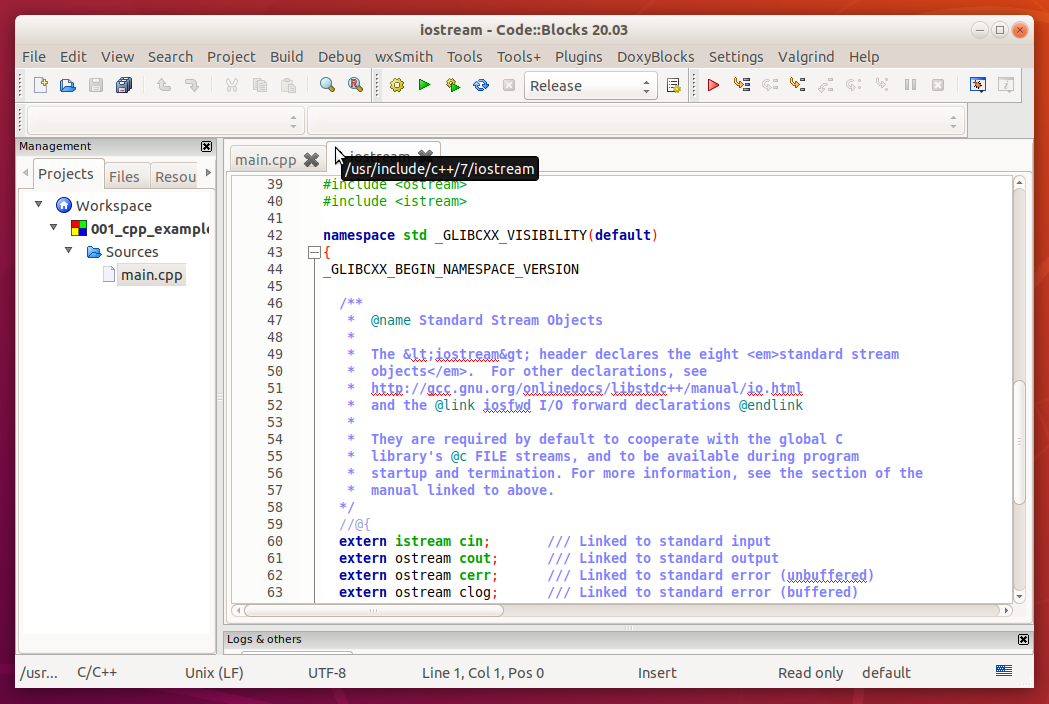
Ha az iostream fájl tartalmát egy másik C++ fordítóhoz mellékelt standard libraryban tekintjük meg, akkor jó eséllyel nem egyezik a képen láthatóval.
A C++ standard library fájljai például itt találhatóak Linuxon (Ubuntu disztribúció):
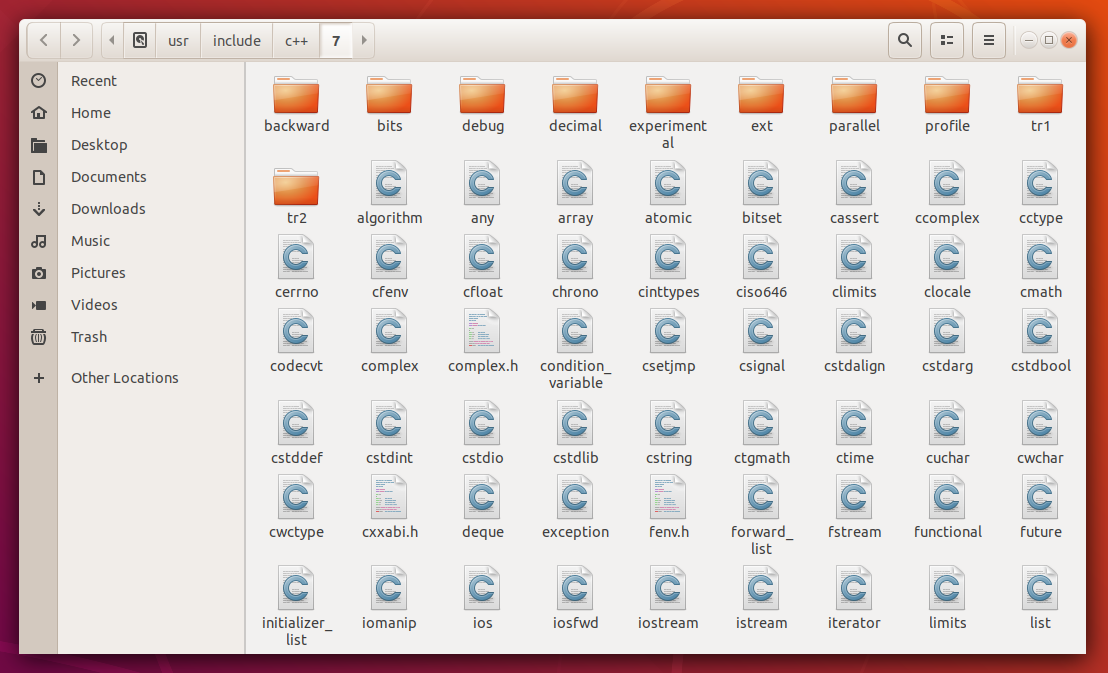
Érdemes tudni, hogy ezek közül nem mindegyik fájl a C++ standard library része, elképzelhető, hogy az operációs rendszer vagy az éppen használt fordító is biztosít néhány rendszerspecifikus dolgot, ami másik operációs rendszeren, vagy másik fordítóval nem áll rendelkezésre.
A különböző C++ fordítókhoz tartozó standard libraryk fájljait a githubon is megtalálhatjuk: g++, msvc, clang
Persze ezen fájlok tartalmát nem kell érteni, csak érdekességképp szerepel ez a tananyagban, hogy lássuk, tényleg léteznek a C++ standard library fájljai :)
Tippek ha majd a C++ standard librarynek egyszerre több fájlját is használjuk
A preprocesszornak szóló utasításokat a programjaink forrásfájljainak az elejére szoktuk írni.
Fontos, hogy ha több preprocesszornak szóló utasítás (úgynevezett preprocesszor direktíva) szerepel a forráskódunk elején, akkor azokat külön sorba írjuk.
Elképzelhető, hogy mások kódjában találkozunk ezzel a preprocesszor direktívával, de ez nem szabványos, csak a g++ fordítóval működik:
#include <bits/stdc++.h>Ez a standard library összes header fájljának tartalmát bemásolja a forráskódnak arra a részére, ahol ez az utasítás szerepel.
Próbáljuk meg csak azokat a header fájlokat includeolni, amiknek a tartalmát használni is fogjuk. Ez az első példaprogramok esetén nem olyan nehéz. Nagyobb programokban ahogy módosítgatjuk a forrásfájlokat, jó eséllyel előbb-utóbb lesz benne fölösleges include. Ezeknek a felderítésében nyújt segítséget az iwyu (include what you use) nevű program.
Alapvető kód
Eddig tehát ebből áll a programunk forráskódja, de még ez a program sem ír ki a parancssorba általunk megadott szöveget, ha lefordítjuk, és elindítjuk:
#include <iostream>
int main(){}Tekinthetjük úgy, hogy ezt minden C++ nyelven írt program forráskódjának tartalmaznia kell, amivel parancssoros műveleteket végzünk.
Szöveg parancssorba való kiírását elvégző utasítás
Ha az #include <iostream> szerepel a forrásfájlunk elején, akkor abban a forrásfájlban használhatunk szövegek parancssorba való kiíratásához utasításokat.
Egy ilyen utasítás például:
std::cout << "example text";Amely a parancssorba az example text szöveget írja ki.
A C++ a C nyelvből megörökölt néhány függvényt, ami szintén szövegek parancssorba való kiíratásához használható. Ezeket nem nagyon fogjuk használni a tananyag további részeiben, egyes C++ programozók kerülendőnek is tartják a C++ kódban való használatukat (lásd: [1], [2] ), de mivel mások kódjában találkozhatunk velük, ezért érdemes lehet tudni a létezésükről.
Ha csak ezeket szeretnénk használni, akkor az #include <cstdio> preprocesszor utasítást is használhatjuk az iostream helyett, viszont ha az std::cout-ot is használni szeretnénk, akkor a cstdio helyett használjuk az #include <iostream> preprocesszor utasítást.
printf("example text");fprintf(stdout, "example text");puts("example text");fputs("example text", stdout);Nem nehéz kitalálni, hogy mindegyik utasításban az idézőjelek közötti szöveget írja ki a program a parancssorba, ha az utasítás a megfelelő helyen (például a main függvény kapcsos zárójelei között) szerepel a forráskódjában.
Fontos, hogy C++-ban a több karaktert tartalmazó szövegeket nem tehetjük aposztrófok közé (mint például a Javascript vagy PHP nyelvekben).
Aposztrófok közé C++-ban csak egy karakter értéket írhatunk.
Például:
'y''3'alsóvonal, underscore:
'_'szóköz, space:
' 'Nem az a lényeg, hogy a két aposztróf között technikailag egyetlen karakter legyen. Vannak olyan speciális karakterek, amiknek a jelölésére két vagy több karaktert használunk, pl. az újsor (más néven sortörés, sorvége, soremelés) karaktert \n-el jelöljük, és például ezt is írhatjuk aposztrófok közé:
'\n'Nem hiba, ha egyetlen karaktert idézőjelek közé teszünk, de érdemes inkább aposztrófokkal jelölni, ha egy karakterről van szó, vagyis például "\n" helyett írjunk '\n'-t.
Egy karakter kiíratása például ezekkel az utasításokkal végezhető el (ebben a példában egy újsor/sortörés karaktert íratunk ki):
std::cout << '\n';std::cout.put('\n');printf("%c",'\n');fprintf(stdout, "%c",'\n');putchar('\n');putc('\n', stdout);fputc('\n', stdout);A tananyag további részeiben ezek közül inkább csak az elsőt és a másodikat fogjuk használni.
A puts() és fputs() függvény nem használható aposztrófok között megadott karakterek kiíratásához, szövegek kiíratásában viszont gyorsabb a printf() és fprintf() függvényeknél.
A fenti példákból látható, hogy egy függvényhívás (egy függvény végrehajtását megkísérlő kifejezés/utasítás) tipikusan úgy néz ki, hogy a függvény neve után kerek zárójelek között vesszővel elválasztva felsoroljuk a függvény bemenő adatait (ezeket aktuális paramétereknek vagy argumentumoknak szokták nevezni), vagyis azokat az adatokat, amiket a függvénynek átadunk, amiket a függvény feldolgoz. A kerek zárójeles részt összefoglaló néven paraméterlistának nevezik.
A legelső példa is felírható olyan formában, mint ahogy egy függvényhívás tipikusan kinéz. Ez a két utasítás tehát ugyanazt jelenti, de az alsó használata (a kipróbálást, tesztelgetést leszámítva) kerülendő:
std::cout << "example text";operator<<(std::cout, "example text");Ez utóbbi főleg akkor lenne átláthatatlan, ha nem csak egyetlen szöveget szeretnénk kiíratni, hanem több (jellemzően különböző típusú) dolgot. Különböző típusú dolgok kiíratására majd a tananyag későbbi részeiben lesz példa, de két szöveg ily módot történő kiíratásával is elég jól szemléltethető, hogy ezt az utasítást nem ebben a formában érdemes használni:
operator<<(operator<<(std::cout, "first\n"), "second\n");Az << egy operátor (műveleti jel), ebben a kontextusban valójában egy függvény (egyébként nem minden operátor függvény), angolul insertion operatornak nevezik. Itt most azt jelöli, hogy kimenetről beszélünk (más kontextusban jelölhet bitenkénti eltolást is, de abban az esetben nem függvény, hanem elemi művelet, akárcsak egy összeadás vagy szorzás hétköznapi számok esetén).
Többféle kimenet létezik, ezt az operátort használhatjuk például akkor is, amikor parancssorba szeretnénk kiírni valamit, illetve fájlba történő írásnál is, valamint std::stringstreamek esetén, melyek későbbi tananyagrész témái.
Azoknak az operátoroknak, amik valójában függvények, pont az a lényege, hogy ne függvényhívás formájában kelljen megadni a paramétereket.
A fenti példákban az std::cout (ami a character output rövidítése) és az stdout (ami a standard output rövidítése) a kimenet célját határozza meg, ami nem mindig a parancssort jelenti, de alapesetben igen. Például Unix/Linux-szerű rendszereken parancssorban egy program kimenetét át lehet irányítani egy fájlba.
Erre csak mellékesen tértem ki, ebben a tananyagban nem fogjuk átirányítani a példaprogramjaink standard outputját fájlba. Lesz majd részletesebb tananyagrész arról is, hogy egy parancssoros programból hogyan tudunk (átirányítás nélkül) fájlba írni.
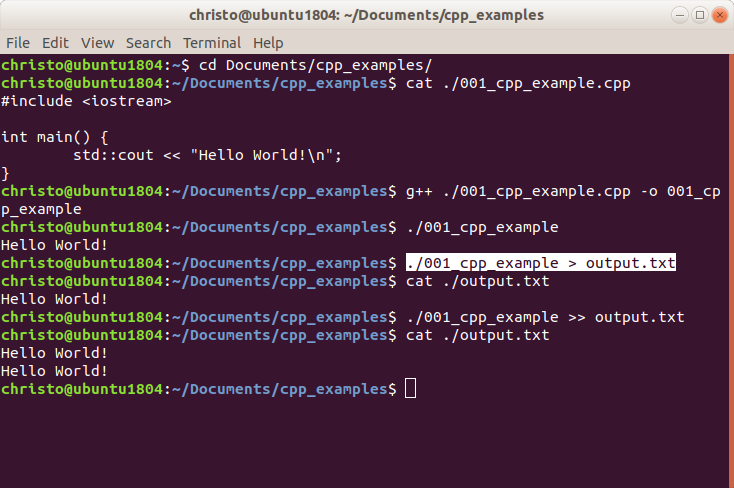
Az std::cout egyébként jóval többet tud annál, minthogy a kimenet célját, vagyis a standard outputot jelölje. Például formázással kapcsolatos beállításokat tárol, de ezekről későbbi tananyagrészben lesz szó.
Sortörés a parancssorba kiírt szövegben
Szokás egy újsor karaktert is tenni a parancssorba kiírni kívánt szöveg végére, hogy ami a parancssorba ezen egyszerű példaprogram futását követően majd kiíródik, ne íródjon egy sorba a példaprogram által kiírt szöveggel, mint ahogy az az alábbi kép legalsó sorában látható:
A sorvége jelet többek között a \n speciális karakter jelenti (a newline, azaz újsor rövidítése). Ha ezt beleírjuk a parancssorba kiírni kívánt szöveg végére, akkor a program kimenetével nem íródik egy sorba ezen példa esetén a parancssor következő szövege, illetve ha szerepelne egy következő utasítás is, amivel szöveget íratunk ki a parancssorba, akkor az is új sorba íródna.
std::cout << "example text\n";Az std::endl függvény is használható újsor kiírására, de ezt nem írhatjuk az idézőjelek közé, hanem egy újabb insertion operátort követően sorolhatjuk fel.
std::cout << "example text" << std::endl;Az endl valójában egy függvény, lehetne ilyen alakban is írni, de ekkor külön utasításként kell írni, nem pedig egy insertion operátor paramétereként:
std::endl(std::cout);Az első példaprogramjaink otthoni tesztelgetése esetén mindegy, hogy '\n'-t használunk vagy std::endl-t. Ezt leszámítva az std::endl használata kerülendő (bővebb indoklás: [1], [2], [3], [4]), lényegében azért, mert lassabb, mint a '\n', értelme viszont kevés esetben van.
A puts() függvény a parancssorba kiírt szöveg után automatikusan tesz sortörést, az fputs() függvény viszont nem.
Az első C++ példaprogram forráskódja
Tipikusan a Hello World! szöveg szokott lenni, amit az első programozós példákban kiíratunk.
#include <iostream>
int main() {
std::cout << "Hello World!\n";
}A szöveg kiírását elvégző utasítást például a main függvény blokkjába (kapcsos zárójelei közé) lehet írni (illetve ha majd lesznek más függvények is a programjainkban, akkor esetleg azoknak a blokkjába is).
forráskód tagolása, alapvető szintaktikai szabályok
Fontos, hogy a C++ nyelvben pontosvesszőt kell tenni az utasítások végére (az elhagyása fordítási hibát eredményez).
Más programozási nyelvekben előfordulhat, hogy nem kötelező vagy nem is szabad pontosvesszőt tenni az utasítások végére.
A C++ nyelv forráskódjában a legtöbb helyen számít a kis- és nagybetű. Ha például a fenti példaprogram kódjában int helyett Int-et írunk vagy cout helyett Cout-ot írunk, fordítási hibát kapunk.
Az elírások (angolul typoo) az esetek túlnyomó részében fordítási hibát eredményeznek (ha esetleg nem, akkor pedig jó eséllyel nem megfelelően működő programot). Elírás például ha std helyett sdt-t írunk, vagy ha iostream helyett iostrem-t. Elírásokat a jártasabb programozók is elkövetnek, például ha nem a megszokott billentyűzetet használják.
Érdemes külön sorba írni az utasításokat a jobb átláthatóság miatt.
Érdemes a kapcsos zárójelek között minden sort beljebb kezdeni (egységesen egy tabulátorral, 4 szóközzel vagy 2 szóközzel), ahogy például a fenti példaprogram kódja esetén is látható. Sokan inkább a szóközt preferálják a tabulátorral szemben, mivel a tabulátorok mérete különböző rendszereken eltérő lehet.
Ha esetleg több blokk (kapcsos zárójelek közötti rész) van egymásba ágyazva, akkor minden egyes blokk esetén kezdjük beljebb a sorokat.
Ezt indentálásnak nevezzük és a C++ nyelvben csak az átláthatóságot javítja, fordítási hibát nem okoz ha nem tartjuk be (például Python és Haskell nyelvekben a rossz indentálás fordítási hibát vagy nem megfelelően működő programot eredményezhet).
Ebben a tananyagban 2 szóközt használunk az indentálásnál, de ha valaki bemásolja a kódokat egy Code Editorba (pl. VSCode), vagy IDE-be (Codeblocks), akkor ott jó eséllyel egy jobb kattintás, majd "Format Document" megoldja, hogy pl 4 szóközzel vagy tabbal legyen indentálva minden.
Arról jókat lehet vitatkozni, hogy a blokkok esetén az első kapcsos zárójel a sor végén vagy a következő sor elején szerepeljen. Mindkettővel találkozhatunk mások forráskódjában.
Akár az is lehet, hogy egy forráskódon belül találkozunk mindkettővel, ekkor viszont különböző típusú blokkok esetén használják az egyiket vagy a másikat.
int main() {
}int main()
{
}A fenti példaprogram kódja esetén a preprocesszor direktívának mindenképp külön sorban kell szerepelnie, de a kód többi részével akár azt is megtehetnénk, hogy a main függvényt és a benne lévő utasítást egyetlen sorba írjuk. Ez nem okoz fordítási hibát, és természetesen ennél a rövid példaprogramnál a kód átláthatósága sem változik különösebben, de hosszabb forráskódoknál érdemes a fenti példaprogram mintáját nagyjából betartani (a blokkok elejét jelző első kapcsos zárójelet például nem baj, ha a következő sorban kezdjük).
#include <iostream>
int main() { std::cout << "Hello World!\n"; }A C++ nyelv forráskódja úgynevezett tokenekből áll. Ezek például szavak vagy írásjelek, amiket egybe kell írni, nem szerepelhet bennük szóköz, tabulátor vagy újsor, különben fordítási hibát kapunk. Például a << vagy a :: operátort egybe kell írni, nem tehetünk szóközt, újsort vagy tabulátort a két < vagy : írásjel közé, de az int vagy a main szavakat is egybe kell írnunk.
A C++ nyelv tokenjei közé tetszőleges szóközt, tabulátort, újsort tehetünk. Természetesen nem szoktuk így írni a forráskódunkat, de jó tudni, hogy a túl hosszú sorokat az egyes tokenek között esetleg tudjuk tördelni.
#\
i\
n\
c\
l\
u\
d\
e\
\
<\
i\
o\
s\
t\
r\
e\
a\
m\
>
int
main
(
)
{
std
::
cout
<<
"Hello World!\n"
;
}Az operátorok és szeparátorok (jellemzően az írásjelek) akár egybe is írhatók az előttük és mögöttük szereplő szavakkal, de például az int és a main szavak nem írhatók egybe, különben fordítási hibát kapunk.
#include<iostream>
int main(){
std::cout<<"Hello World!\n";
}return 0; utasítás a main függvény végén
A main függvény blokkjának végén (a záró kapcsos zárójel előtt) szokott szerepelni egy return 0; utasítás, aminek az elhagyása nem jár semmilyen következménnyel, illetve nem tekintendő hibának, de sokan kiírják a teljesség kedvéért.
A return 0; technikailag azt jelenti, hogy a függvény a hívó félnek (a main függvényt az operációs rendszer hívja meg) visszaad egy 0 értéket (ez a main függvény kimenete, eredménye, amit a programozásban visszatérési értéknek (angolul return value) nevezünk). A 0 érték a main függvény esetén megegyezés szerint azt jelenti, hogy a program futása hiba nélkül lefutott, a 0-tól eltérő érték pedig valamilyen hibát jelent. 0-tól eltérő értéket (jellemzően pl. 1-et) nem a main függvény utolsó utasításaként szoktunk használni, hanem a main függvény blokkján belül valahol valamilyen feltétel teljesülése esetén, amiről majd későbbi tananyagban lesz szó. A main függvény által visszaadott értéket sztátuszkódnak is szokták nevezni.
#include <iostream>
int main() {
std::cout << "Hello World!\n";
return 0;
}Fontos: amit a return 0; utasítás és a main függvény blokkját lezáró kapcsos zárójel közé írunk, azok az utasítások nem kerülnek végrehajtásra, másképp fogalmazva a main függvény blokkjában elhelyezett return 0; utasítás a program futásának befejezését jelenti. Sőt, előfordulhat, hogy erről a fordító nem is figyelmeztet.
return EXIT_SUCCESS; utasítás a main függvény végén
Esetleg találkozhatunk a return EXIT_SUCCESS; és return EXIT_FAILURE; utasításokkal is, de ezek használatához a C++ standard library cstdlib header fájlját is includeolnunk kell.
Az EXIT_SUCCESS és az EXIT_FAILURE úgynevezett preprocesszor makrók, ami azt jelenti, hogy a fordítás megkezdése előtt a preprocesszor végignézi a teljes forráskódot, és ahol EXIT_SUCCESS-t vagy EXIT_FAILURE-t talál, azt kicseréli egy olyan értékre, ami a cstdlib fájlban van megadva, mely értékek különböző rendszereken eltérőek lehetnek.
A legnépszerűbb asztali számítógépes operációs rendszereken a legismertebb fordítók esetén az EXIT_SUCCESS jó eséllyel 0-ra lesz kicserélve, az EXIT_FAILURE pedig 1-re, de ha esetleg a kódunkat olyan rendszeren fordítanánk, ami más sztátusz kódokat használ (pl. egyes mainframe számítógépek), az EXIT_SUCCESS és EXIT_FAILURE makrók segítségével akkor is helyesen fog működni a programunk.
#include <iostream>
#include <cstdlib>
int main() {
std::cout << "Hello World!\n";
return EXIT_SUCCESS;
}Kíváncsiságból akár meg is nézhetjük különböző fordítókat használva, hogy mire helyettesíti az EXIT_SUCCESS és EXIT_FAILURE preprocesszor makrókat a preprocesszor, például ha egyszerűen cout-tal kiíratjuk az értéküket:
std::cout << EXIT_SUCCESS << '\n';
std::cout << EXIT_FAILURE << '\n';Ez a két utasítás a manapság legelterjedtebb asztali számítógépeken (beleértve a laptopokat), a legismertebb operációs rendszereket használva jó eséllyel 0-át és 1-et ír ki.
exit(0) utasítás;
Mások forráskódjában esetleg találkozhatunk az exit(0); vagy std::exit(0); (vagy hiba esetén pl. exit(1);) utasítással is, melynek használata kerülendő (bad practice), mert nem szabadítja fel teljesen a program által lefoglalt memóriát, későbbi tananyagrészben lesz szó arról, hogy mit használjunk helyette.
Persze az első parancssoros példaprogramjaink kevés helyet foglalnak a számítógép memóriájában, ezért jó eséllyel nem okoz tragédiát az exit() függvény használata, de talán már most érdemes lehet megemlíteni, hogy későbbi tananyagrészek megértése után mire érdemes majd törekedni.
std névtér, using namespace std; utasítás
Az std az angol standard (szabványos) szó rövidítése. Angolul sztúd-nak szokták ejteni, lásd ebben a videóban 12 másodpercnél.
Az egyszerű példaprogramokban könnyen találkozhatunk a következő utasítással is, jellemzően a preprocesszor direktívák után:
using namespace std;A C++ nyelvhez a standard libraryn kívül sok egyéb library készült, ezért gondolni kellett arra is, hogy ha valaki egy másik libararyt is használ, akkor abban lehet, hogy van egy vagy több dolog, aminek/amiknek a neve egyezik azokkal ami a standard libraryban is megtalálható. Ha használni szeretnénk a programunkban két olyan libraryt amik azonos nevű dolgokat tartalmaznak, névütközés (angolul naming conflict vagy naming collision) léphet fel, ami fordítási hibát eredményez. A névütközések elkerülésére találták ki a névtereket. Nem csak a különböző librarykhez lehet névtereket használni, hanem akár egy nagyobb program különböző részeihez is.
A standard libraryben lévő dolgok jellemzően az std nevű névtérbe lettek belepakolva. Ha el akarunk érni valamit a standard libraryből, akkor vagy mindenhol jelölnünk kell az std névteret, ahol csak hivatkozunk az adott dologra (mint ahogy a cout és endl esetén láthattuk), vagy ha használjuk a using namespace std; utasítást egy forrásfájlban, akkor ott az utasítást követően nem kell jelölnünk az std névteret.
#include <iostream>
using namespace std;
int main() {
cout << "Hello World!" << endl;
}Érdemes megjegyezni, hogy a using namespace std; utasítás használatát sokan kerülendő példának (angolul bad practice) tekintik, mert névütközést okozhat (tulajdonképpen amely probléma megoldására a névterek ki lettek találva, azt a problémát hozza elő), elképzelhető, hogy egyes helyeken meg is van tiltva a használata. Természetesen az első példaprogramjainkban nem baj, ha használjuk a using namespace std; utasítást, bár annyiból inkább érdemes kerülni a használatát, hogy megtanuljuk, hogy mik vannak az std névtérben.
- isocpp.com - using namespace std
- C++ Weekly - Stop Using using namespace (videó)
- stackoverflow.com - why using namespace std considered bad practice?
Esetleg azt is érdemes lehet tudni, hogy nem csak az egész std névteret tudjuk feloldani, hanem az egyes elemeit is, például a cout-ot és endl-t a következő két utasítással:
using std::cout; using std::endl;Ha egy utasításban vesszővel elválasztva soroljuk fel őket, azt nem minden fordító fogadja el:
using std::cout, std::endl;Arra is van lehetőség, hogy a using namespace std; utasítást egy függvény blokkjába írjuk bele, és akkor csak abban a függvényben lévő utasításokra lesz érvényes. Persze az első példaprogramjainkban csak egyetlen függvényt definiálunk, ez pedig a main függvény, így ezeknél a példáknál semmiben nem különbözik a preprocesszor direktívák után elhelyezett using namespace std; utasítástól, ha ugyanezt az utasítást a main függvény első sorába írjuk, viszont érdemes lehet tudni róla, hogy később esetleg ez a megoldás is jól jöhet.
Egyéb kapcsolódó tananyag
- cplusplus.com - structure of a program
- C++ Weekly - Learning Modern C++ - 2: Hello World (videó)
- C++ For The Beginner and Non-Programmer - Lesson 1 (videó)
- C++ Weekly - Hello World, Hello Commodore (videó)
Előző tananyagrész: első lépések
Következő tananyagrész: megjegyzések (kommentek) a forráskódban



